Node 学习笔记
第一章:Node.js 世界
一、认识 Node.js
官方网站地址:https://nodejs.org/en
中文网站地址:https://nodejs.cn
1. 什么是 Node.js
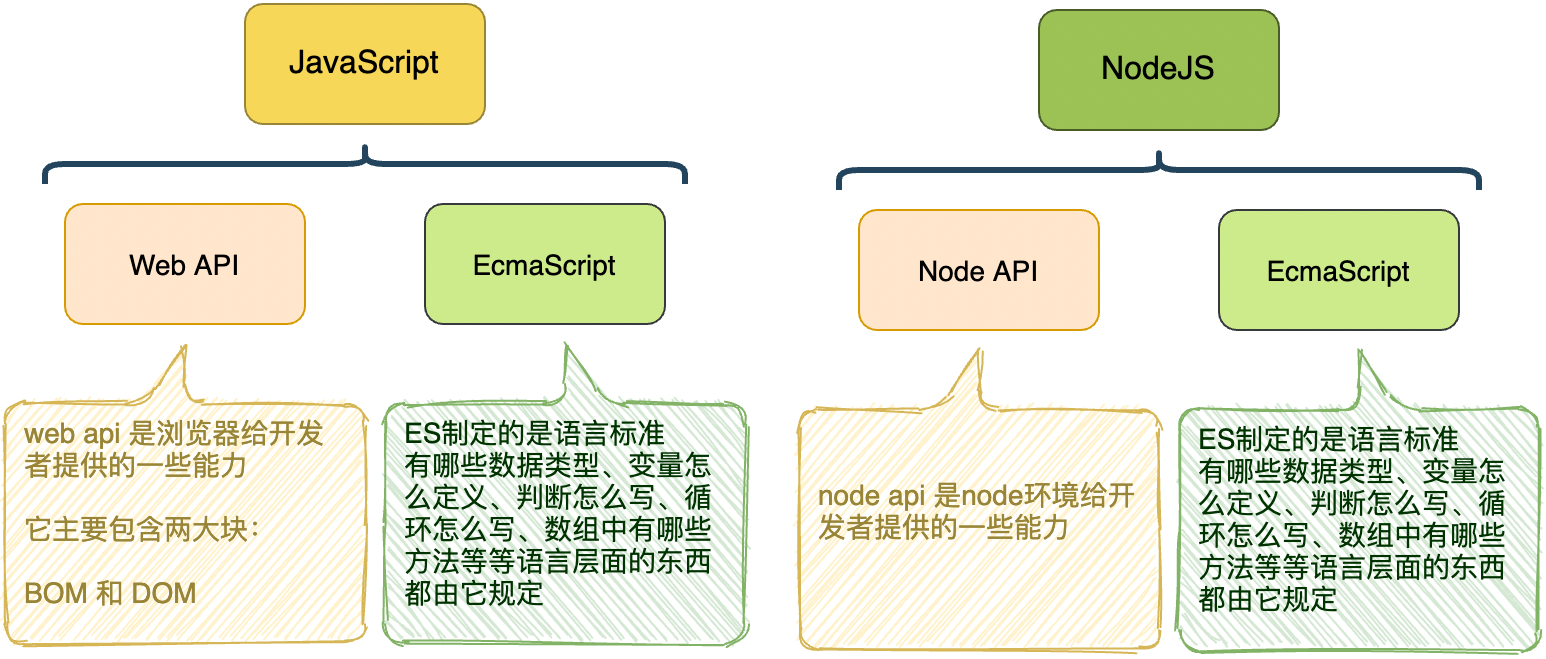
Node.js 也称 Node,是一个基于 Chrome V8 引擎的开源、跨平台的 JavaScript 运行时环境(宿主)。
注意:
Node.js 不是一种独立的语言。与 PHP、Python、Perl、Ruby 的”既是语言也是平台” 不同。

- Node.js 也不是一个 JavaScript 框架或库。不同于 Vue.js、React.js、Angular、jQuery 等。
- 运行在 Node.js 上的 JavaScript 不能使用 DOM、BOM,但可以使用 Node.js 提供的各种 API(文件系统读写、网络 IO、加密、压缩解压文件等操作)。
2. 为什么学习 Node.js
前端可以实现工程化开发。
前端自动化工具、模块化打包工具 gulp、webpack 以及 vue、react 的脚手架工具都是基于 Node 运行的。
可以使用 JavaScript 进行后端开发,前端工程师秒变全栈工程师。
使用 JS 开发很多小工具,如自动化脚本,爬虫程序等。
3. Node.js 的特点
1)单线程
在 Java、PHP 或者 .net 等服务器端语言中,会为每一个客户端连接创建一个新的线程。而每个线程需要耗费大约 2MB 内存。也就是说,理论上,一个 8GB 内存的服务器可以同时连接的最大用户数为 4000 个左右。要让 Web 应用程序支持更多的用户,就需要增加服务器的数量,而 Web 应用程序的硬件成本当然就上升了。
Node.js 不为每个客户连接创建一个新的线程,而仅仅使用一个线程。当有用户连接了,就触发一个内部事件,通过非阻塞 I/O、事件驱动机制,让 Node.js 程序宏观上也是并行的。使用 Node.js,一个 8GB 内存的服务器,可以同时处理超过 4 万用户的连接。
另外,单线程带来的好处,还有操作系统完全不再有线程创建、销毁的时间开销。
坏处,就是一个用户造成了线程的崩溃,整个服务都崩溃了,其他人也崩溃了。
2)非阻塞 I/O (non-blocking I/O)
例如,当在访问数据库取得数据的时候,需要一段时间。在传统的单线程处理机制中,在执行了访问数据库代码之后,整个线程都将暂停下来,等待数据库返回结果,才能执行后面的代码。也就是说,I/O 阻塞了代码的执行,极大地降低了程序的执行效率。
由于 Node.js 中采用了非阻塞型 I/O 机制,因此在执行了访问数据库的代码之后,将立即转而执行其后面的代码,把数据库返回结果的处理代码放在回调函数中,从而提高了程序的执行效率。
当某个 I/O 执行完毕时,将以事件的形式通知执行 I/O 操作的线程,线程执行这个事件的回调函数。为了处理异步 I/O,线程必须有事件循环,不断的检查有没有未处理的事件,依次予以处理。
阻塞模式下,一个线程只能处理一项任务,要想提高吞吐量必须通过多线程。而非阻塞模式下,一个线程永远在执行计算操作,这个线程的 CPU 核心利用率永远是 100%。所以,这是一种特别有哲理的解决方案:与其人多,但是好多人闲着;还不如一个人玩命,往死里干活儿。
3)事件驱动 (event-driven)
Node.js 的事件循环机制允许你在执行一个回调函数时,转而执行其他事件,但不是在同一个回调函数执行过程中。而是通过将回调函数放入事件队列,并由事件循环来调度执行。
Node.js 底层是 C++(V8 也是 C++ 写的)。底层代码中,近半数都用于事件队列、回调函数队列的构建。用事件驱动来完成服务器的任务调度,这是鬼才才能想到的。针尖上的舞蹈,用一个线程,担负起了处理非常多的任务的使命。
4. 架构
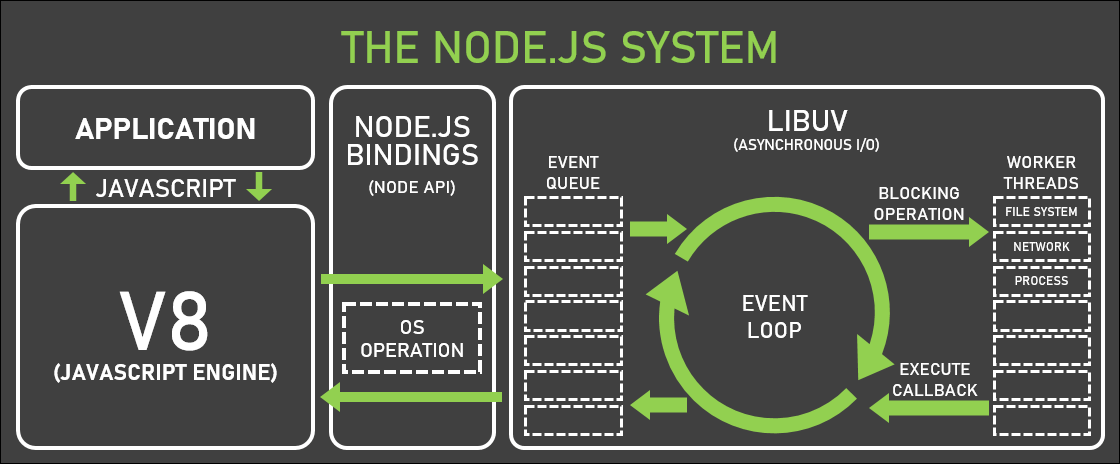
这幅图展示的是 Node.js 的运行机制。Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境,它使用了非阻塞的事件驱动的 I/O 模型。这个图解说明了 Node.js 应用程序如何与底层的系统交互,包括以下几个主要部分:
- 应用程序(Application):这是开发者使用 JavaScript 编写的代码部分。
- V8(JavaScript Engine):这是 Google 开发的开源 JavaScript 引擎,用于解释和执行用户的 JavaScript 代码。
- Node.js 绑定(Node.js Bindings):这是 Node.js 的核心 API,它提供了一些方法,允许 JavaScript 代码与操作系统进行交互。
- 事件队列(Event Queue):这是一个队列,用于存放事件和对应的回调函数。
- 事件循环(Event Loop):这是 Node.js 的核心,负责不断地从事件队列中取出事件和回调函数执行。事件循环是非阻塞的,确保 Node.js 可以处理大量的并发而不会停滞。
- LIBUV:这是一个专门处理异步 I/O 的库,提供了跨平台的 I/O 功能。
- 工作线程(Worker Threads):对于一些可能会阻塞事件循环的操作(如密集型文件操作、网络请求等),Node.js 会使用工作线程来处理,这样可以确保事件循环不会因为这些耗时操作而被阻塞。
整个流程大致是:应用程序通过 Node.js API 发起非阻塞 I/O 操作,这些操作被放入事件队列中,事件循环不断地处理这些事件,并在操作完成后调用相应的回调函数。如果操作是计算密集型或阻塞型的,则通过工作线程来处理,以免阻塞事件循环。这种模型使得 Node.js 能够高效地处理大量的并发连接,特别适合 I/O 密集型的应用。
Node.js 的"单线程"指的是什么?
✅ JavaScript 执行是单线程的。
❌ Node.js 系统整体不是单线程的。
5. 安装
1)Linux 安装
[1] 去官网下载
英文网址:https://nodejs.org/en/download
中文网址:http://nodejs.cn/download
历史版本下载:https://npmmirror.com/mirrors/node/
备注:通过 uname -a 命令可查看 Linux 系统位数(x86_64 表示 64 位系统, i686、i386 表示 32 位系统)。
建议:推荐 Visual Studio Code 安装一个 Code Runner 插件。
[2] 上传 & 解压
2.1 上传到服务器
目录可以是任意路径,目前我放置在 /opt 路径下。
cd /opt
wget https://nodejs.org/dist/v20.6.1/node-v20.6.1-linux-arm64.tar.xz2.2 解压
解压后的文件我这边将名字改为了 nodejs,这个地方自己随意,只要在建立软连接的时候写正确就可以。
tar -xvf node-v20.6.1-linux-arm64.tar.xz
mv node-v16.13.0-linux-x64 nodejs[3] 建立软连接变为全局
3.1 检查
确认下 nodejs 下 bin 目录里是否有 node 和 npm文件,如果有执行软连接,没有重新执行上面的步骤。
3.2 建立软连接,变为全局
ln -s /opt/nodejs/bin/npm /usr/local/bin/
ln -s /opt/nodejs/bin/node /usr/local/bin/[4] 测试是否安装成功
# 显示 node.js 版本
node -v2)NVM
[1] 介绍
nvm 全称 Node Version Manager。顾名思义它是用来管理 node 版本的工具,方便切换不同版本的 Node.js。
[2] 使用
nvm 的使用非常的简单,跟 npm 的使用方法类似。
下载安装
首先先下载 nvm,下载地址:https://github.com/coreybutler/nvm-windows/releases。
选择 nvm-setup.exe 下载即可。
常用命令
| 命令 | 说明 |
|---|---|
| nvm list available | 显示所有可以下载的 Node.js 版本 |
| nvm list | 显示已安装的版本 |
| nvm install 18.12.1 | 安装 18.12.1 版本的 Node.js |
| nvm install latest | 安装最新版的 Node.js |
| nvm uninstall 18.12.1 | 删除某个版本的 Node.js |
| nvm use 18.12.1 | 切换 18.12.1 的 Node.js |
二、Node.js 必知
1. Node 程序传递参数
可以通过命令行向程序传递参数。这些参数可以在程序中通过 process.argv 访问。process.argv 是一个包含命令行参数的数组。第一个元素是 'node 程序安装位置',第二个元素是 JavaScript 文件的路径。接下来的元素将是任何额外的命令行参数。
例如,如果有以下的 Node.js 程序:
// myscript.js
console.log(process.argv);然后通过命令行运行这个程序,并传递一些参数:
node myscript.js hello world将会看到以下的输出:
[ 'C://Program Files//nodejs//node.exe',
'/path/to/myscript.js',
'hello',
'world'
]2. Node 的输出
最常用的输入内容的方式:
// 最常用的输出内容的方式
console.log()
// 清空控制台
console.clear()
// 打印函数的调用栈
console.trace()3. 全局对象
1)特殊的全局对象
为什么我称之为特殊的全局对象呢?这些全局对象实际上是模块中的变量,只是每个模块都有,看起来像是全局变量。
包括:__dirname、__filename、module、exports、require()。
注意:在命令行交互中是不可以使用的。
// 获取当前文件所在的绝对路径
__dirname
// 获取当前文件所在的绝对路径+文件名
__filename2)常见的全局对象
(1) process 对象:process 提供了 Node 进程中相关的信息。比如 Node 的运行环境、参数信息等。
(2) console 对象:提供了简单的调试控制台。
(3) 定时器函数:在 Node 中使用定时器有好几种方式。
setTimeout(callback, delay [, ...args]) :callback 在 delay 毫秒后执行一次。
setInterval(callback, delay [, ...args]) :callback 每 delay 毫秒执行一次。
setImmediate(callback [, ...args]) :callback I/O 事件后的回调的“立即”执行。
这里先不展开讨论它和 setTimeout(callback, 0) 之间的区别;因为它涉及到事件循环的阶段问题,会在后续详细讲解事件循环相关的知识。
process.nextTick(callback [, ...args]) :添加到下一次 tick 队列中。
具体的讲解,也放到事件循环中说明。
(4) new URL('https://example.com');
(5) new URLSearchParams('key=value');
global 和 window 的区别?
环境
- window 存在于浏览器环境。
- global 存在于 Node.js 环境。
API
- window 提供了浏览器相关的 API,如 document, location, history, localStorage, sessionStorage, requestAnimationFrame 等。
- global 提供了 Node.js 相关的 API,如 Buffer, process, global.gc (如果启用了垃圾回收器的手动控制), setImmediate, clearImmediate 等。
默认对象
- 在浏览器环境中,顶层声明的变量和函数默认是 window 对象的属性。
- 在 Node.js 中,顶层声明的变量和函数不会成为 global 对象的属性。因为 Node.js 使用模块系统,每个模块都有自己的作用域。
第二章:Node.js 模块化
推荐阅读:Module 的语法
一、概述
1. 模块化介绍
Node 由模块(每一个 JS 即是一个模块)组成,采用 CommonJS 模块规范(提供了模块引入导出的规则)。每个文件就是一个模块,有自己的作用。在一个文件里面定义的变量、函数、类(class)都是私有的,对其他文件不可见(模块作用域)。在服务器端,模块的加载是运行时同步加载的。
运行时同步加载的?
运行时:模块在代码执行过程中加载,不是预先编译时确定。
同步:require()会阻塞代码执行,直到模块完全加载完成。
模块化是指解决一个复杂问题时,自顶向下逐层把系统划分成若干模块的过程,对于整个系统来说,模块是可组合,分解和更换的单元。
2. 模块化的好处
- 提高代码的复用性。
- 提高代码的可维护性。
- 可以实现按需加载。
- 防止命名冲突。
3. 模块化规范
① CommonJS 规范
CommonJS (CJS) 是一种模块化规范,最初提出来是在浏览器以外的地方使用,并且当时命名为 ServerJS,后来为了体现它的广泛性,更名为 CommonJS,也可以简称为 CJS。Node 是 CommonJS 在服务端一个具有代表性的实现,Browserify 是 CommonJS 在浏览器端的一种实现。webpack 具备对 CommonJS 的支持与转换。
② AMD 规范
AMD 主要是应用于浏览器端的一种模块化规范,AMD 是 Asynchronous Module Definition(异步模块定义)的缩写,它采用的是异步加载模块,事实上 AMD 的规范早于 CommonJS,但是现在 CommonJS 仍被使用,但 AMD 已经很少用了。 实现 AMD 规范的库主要是 require.js 和 curl.js。
③ CMD 规范
CMD 也是应用于浏览器端的一种模块化规范,CMD 是 Common Module Definition(通用模块定义)的缩写,它也是采用了异步加载模块,但是它将 CommonJS 的优点吸收了过来,这个目前也很少使用了。
实现 CMD 规范的库主要是 sea.js。
④ ES Module 规范
ES Module (ESM) 规范是 ES 提出的,是官方的模块化规范。
4. Node 中模块的分类
Node.js 中根据模块来源的不同,将模块分为了 3 大类,分别是:
- 内置模块(由 Node.js 官方提供,例如:fs, path, http)。
- 第三方模块:由第三方开发出来的模块,并非官方提供的内置模块,也不是用户创建的自定义模块,使用前需要先下载。
- 自定义模块:用户创建的每个 JS 文件,都是自定义模块。
Node 支持 CommonJS 和 ES6 两种模块化规范。
二、CommonJS 模块规范
1. 在模块中暴露数据
模块内如果没有暴露数据,引入模块的时候会得到一个空对象。多次导入模块,实际只会执行一次代码,不会报错。
1)通过为 module.exports 赋值,实现暴露数据。module.exports 的值就是要暴露的数据。
module.exports = true;
module.exports = 5211314;
const data = [10,20,30,40,50,60];
module.exports = data;
module.exports = () => {
console.log(123456);
}
// 开发常用
module.exports = {
school: "克莱登大学",
name: "张三",
age: 18
}这样暴露数据,后面的会把前面的覆盖掉。不推荐这种写法。
2)通过为 module.exports 设置属性。module.exports 的默认值是个空对象,可以为空对象添加属性。
module.exports.isNB = true;
module.exports.msg = 'hahaha';
module.exports.say = ()=>{};3)通过为 exports 设置属性,暴露数据。exports 与 module.exports 指向同一个对象,为 exports 设置属性就是为 moudule.exports 设置属性;但不能给 exports 赋值,那样会改变其引用地址,exports 与 module.exports 就不再是一个对象了。
const userName = "张三";
const age = 18;
// 以下方式可以暴露数据
exports.userName = userName; // 等价于 module.exports.userName = userName;
exports.age = age; // 等价于 module.exports.userName = userName;
// 以下写法无法暴露数据,因为修改了 exports 的引用地址
exports = {username, age};2. 导入(引入)模块
通过 require() 方法可以引入模块,该方法的返回值就是模块中暴露的数据。
const 变量名 = require('自定义模块地址');
const {变量1, 变量2} = require('自定义模块地址'); // 如果模块暴露的数据是对象,可以使用结构赋值获取其中的属性方法
// 例子
const mod = require('./mode'); // 等同于 require('./mod.js')Require 方法的文件查找策略?
导入格式如下:require(X)
情况一 核心模块:X 是一个 Node 核心模块,比如 path、http,直接返回核心模块,并且停止查找。
情况二:X 是以 ./ 或 ../ 或 /(根目录)开头的。这是模块文件的相对路径,相对于当前的执行的 JS 脚本的位置,并非命令行打开的目录。
第一步 文件模块:将 X 当做一个文件在对应的目录下查找;
1. 如果有后缀名,按照后缀名的格式查找对应的文件。
2. 如果没有后缀名,会按照如下顺序:
1> 直接查找文件 X
2> 查找 X.js 文件。读取文件内容并编译执行并获取模块中暴露的数据。
3> 查找 X.json 文件。读取文件,用 JSON.parse() 解析返回结果作为获取的数据。
4> 查找 X.node 文件。c/c++ 编写的扩展文件,通过 dlopen() 方法编译。
5> 其他扩展名,文件内容会被当做 JavaScript 代码去解析。
第二步 目录作为模块:没有找到对应的文件,将 X 作为一个目录。
1> 如果使用了目录作为模块名,并且目录中包含一个package.json文件,则Node.js会查找该文件中指定的main入口文件。
2> 查找 X / index.js 文件。
3> 查找 X / index.json 文件。
4> 查找 X / index.node 文件。
总结:自定义模块的地址可以省略扩展名,如果模块路径没有扩展名,会依次查找 .js 文件、.json 文件、目录。
情况三 非原生模块:直接是一个 X(没有路径),并且 X 不是一个核心模块。
1. Node.js 将在当前文件所在目录下的 node_modules 目录中查找名为 X 的模块。如果没有找到,它会移动到上级目录的 node_modules 目录中继续查找,依此类推,直到到达文件系统的根目录。
查找的具体顺序如下:
./node_modules/X
../node_modules/X
../../node_modules/X
../../../node_modules/X
以此类推,直到根目录的 /node_modules/X
2. 全局 node_modules 目录:
如果在上述所有目录中都没有找到模块 X,Node.js 会尝试在全局的 node_modules 目录中查找,这个目录的位置依赖于 Node.js 的安装路径和配置。
如果上面的路径中都没有找到,那么报错:not found模块导入的加载流程
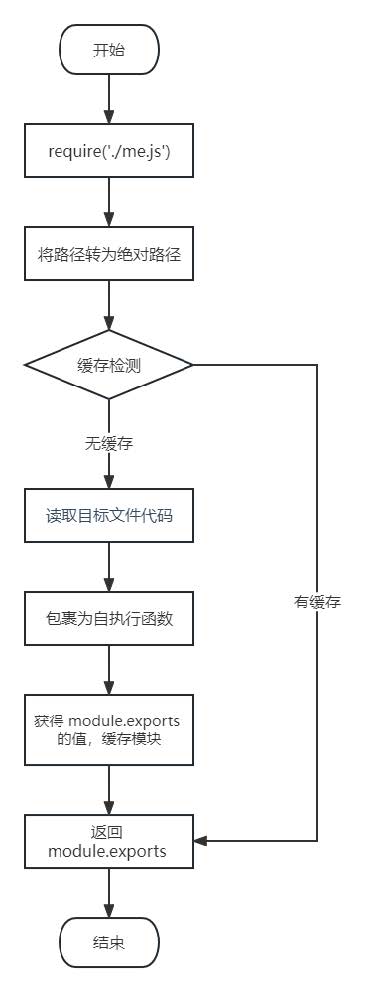
require 导入自定义模块会按照以下流程加载:
① 将相对路径转为绝对路径,定位目标文件。
② 缓存检测。
③ 读取目标文件代码。
④ 包裹为一个函数并执行(自执行函数)。通过 arguments.callee.toString() 查看自执行函数。
⑤ 缓存模块的值。
⑥ 返回 module.exports 的值。
结论一:模块在被第一次引入时,模块中的 js 代码会被运行一次。
模块被多次引入时,会缓存,最终只加载(运行)一次。为什么只会加载运行一次呢?这是因为每个模块对象 module 都有一个属性:loaded。为 false 表示还没有加载,为 true 表示已经加载。
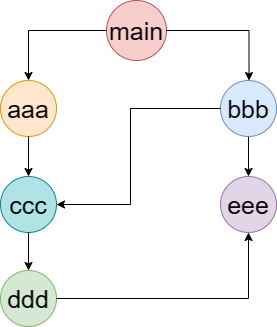
结论二:如果有循环引入,那么加载顺序是什么?图结构在遍历的过程中,有深度优先搜索(DFS, depth first search)和广度优先搜索(BFS, breadth first search)。Node 采用的是深度优先算法:main --> aaa --> ccc --> ddd --> eee --> bbb。
三、ES6 模块规范
1. Node 中使用 ES 模块规范
Node.js 要求 ES6 模块采用 mjs 后缀文件名,也就是说,只要脚本文件里面使用 import 或者 export 命令,那么就必须采用 mjs 后缀名。
如果不希望将后缀名改成 mjs,可以在项目的 package.json 文件中,指定 type 字段为 module。
备注:ESM 是静态依赖(编译时加载),而 CMJ 是动态依赖(运行时加载)。
2. 在模块中暴露数据
① 默认导出(Default Exports)
使用 export default 可以在模块中暴露单个数据。
注意:每个脚本文件中 export default 语句只能出现一次,出现多个 export default 语句会报错!且 export default 后不能是声明语句。
export default 100;
const data = [10,20,30,40,50];
export default data;
function say() {}
function eat() {}
export default {
say,
eat
}本质上,export default 就是输出一个叫做 default 的变量或方法,然后系统允许你为它取任意名字。所以,下面的写法是有效的。
// modules.js
function add(x, y) {
return x * y;
}
export {add as default};
// 等同于
// export default add;
// app.js
import { default as foo } from 'modules';
// 等同于
// import foo from 'modules';② 命名导出(Named Exports)
使用 export 可以暴露多个数据,有两种写法。
// 第一种写法:在声明变量的同时暴露
export const firstName = 'Simei';
export const lastName = 'Bert';
export const year = 1918;
export function fn() {};
export const obj = {name:'张三',age:18}
// 第二种写法:在文件底部统一暴露(推荐)
const firstName = 'Simei';
const lastName = 'Bert';
const year = 1918;
function fn() {};
const obj = {name:'张三',age:100}
// 注意:export 右边的是一种语法结构,并不是 {} 表示的对象
export {firstName, lastName, year, fn, obj}export 后面要么是各种声明语句,要么是 {}。其他都会报错。
3. 引入模块
① 导入默认导出
模块使用 export default 暴露单个数据。
import 变量名 from '模块地址';② 导入命名导出
模块使用 export 暴露多个数据。
// 获取的变量名必须与模块暴露的变量名一致,可以多次分别获取,可以取别名
import {name, year as y} from '模块地址';
import {fn} from '模块地址';③ 导入整个模块
// 可以将模块中的数据整体加载
import * as 别名 from '模块地址';4. export 与 import 的复合写法
如果在一个模块之中,先输入后输出同一个模块,import 语句可以与 export 语句写在一起。
import { foo, bar } from 'my_module';
export { foo, bar };
// 简写
export { foo, bar } from 'my_module';上面代码中,export 和 import 语句可以结合在一起,写成一行。但需要注意的是,写成一行以后,foo 和 bar 实际上并没有被导入当前模块,只是相当于对外转发了这两个接口,导致当前模块不能直接使用 foo 和 bar。
模块的接口改名和整体输出,也可以采用这种写法。
// 接口改名
export { foo as myFoo } from 'my_module';
// 整体输出
export * from 'my_module'; // export * 命令会忽略 my_module 模块的 default默认接口的写法如下。
export { default } from 'foo';具名接口改为默认接口的写法如下。
export { es6 as default } from './someModule';
// 等同于
import { es6 } from './someModule';
export default es6;同样地,默认接口也可以改名为具名接口。
export { default as es6 } from './someModule';ES2020 之前,有一种 import 语句,没有对应的复合写法。
import * as someIdentifier from "someModule";ES2020 补上了这个写法。
export * as ns from "mod"; // export * 命令会忽略 mod 模块的 default。如果需要使用 default,则需要 import exp from 'mod';
// 等同于
import * as ns from "mod";
export {ns};补充:import 函数
通过 import 加载一个模块,是不可以在其放到逻辑代码中的。但是某些情况下,确确实实希望动态的来加载某一个模块。这个时候需要 使用 import() 函数来动态加载。import 函数返回一个 Promise,可以通过 then 获取结果。
let flag = true;
if(flag) {
import('./modules/aaa.js').then(aaa => {
aaa.aaa();
})
} else {
import('./modules/bbb.js').then(bbb => {
bbb.bbb();
})
}5. 实战
导出
export const a = 1; // 具名,常用
export function b() {} // 具名,常用
export const c = () => {} // 具名,常用
const d = 2;
export { d } // 具名
const k = 10
export { k as temp } // 具名
export default 3 // 默认,常用
export default function() {} // 默认,常用
const e = 4;
export { e as default } // 默认
const f = 4, g = 5, h = 6
export { f, g, h as default} // 基本 + 默认
// 以上代码将导出下面的对象
/*
{
a: 1,
b: fn,
c: fn,
d: 2,
temp: 10,
f: 4,
g: 5,
default: 6
}
*/导入
// 仅运行一次该模块,不导入任何内容
import "模块路径"
// 常用,导入属性 a、b,放到变量a、b中。a->a, b->b
import { a, b } from "模块路径"
// 常用,导入属性 default,放入变量c中。default->c
import c from "模块路径"
// 常用,default->c,a->a, b->b
import c, { a, b } from "模块路径"
// 常用,将模块对象放入到变量obj中
import * as obj from "模块路径"
// 导入属性a、b,放到变量temp1、temp2 中
import {a as temp1, b as temp2} from "模块路径"
// 导入属性default,放入变量a中,default是关键字,不能作为变量名,必须定义别名
import {default as a} from "模块路径"
//导入属性default、b,分别放入变量a、b中
import {default as a, b} from "模块路径"
// 以上均为静态导入
import("模块路径") // 动态导入,返回一个Promise,完成时的数据为模块对象6. ES Module 的解析流程
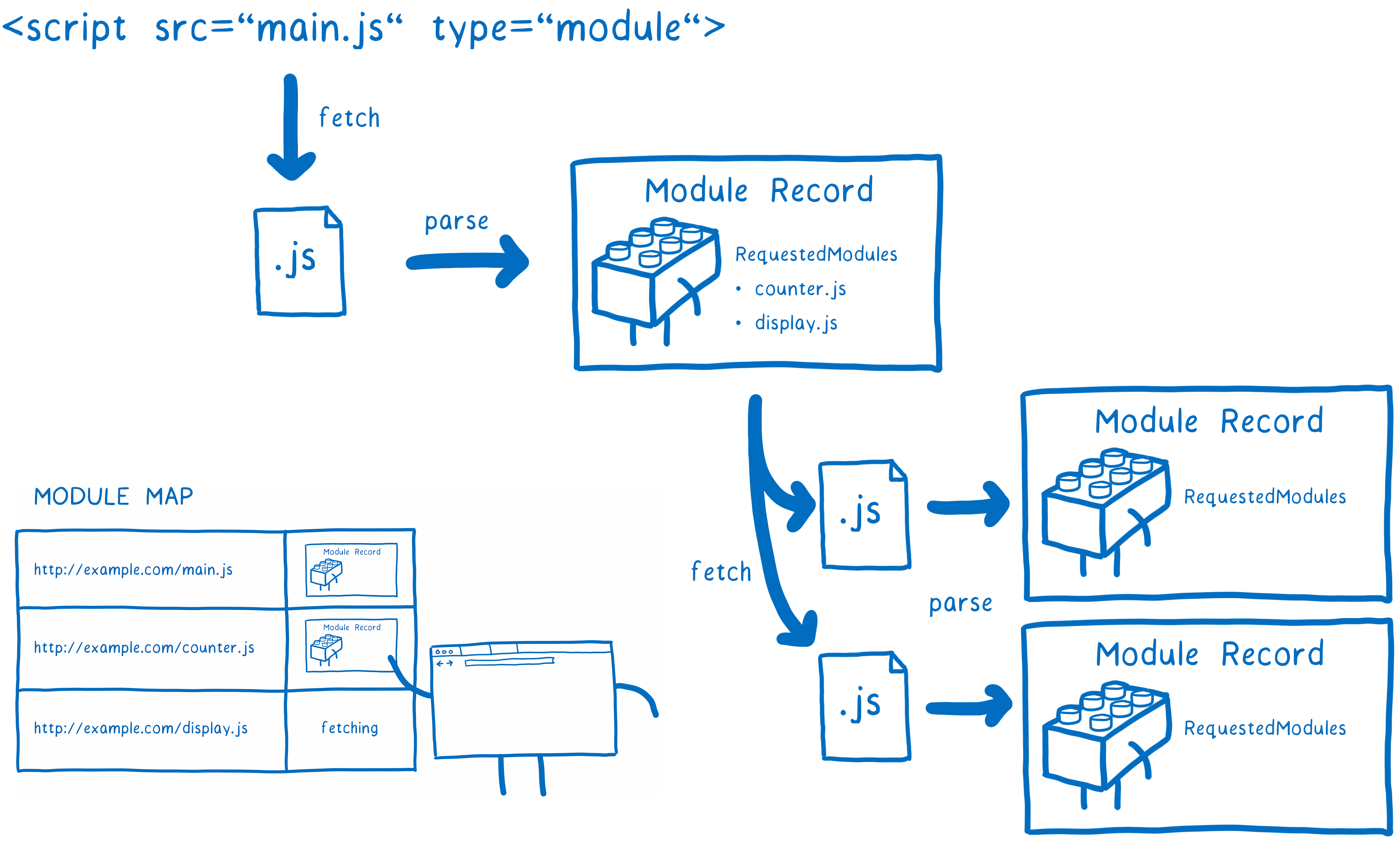
ES Module 的解析过程可以划分为三个阶段:
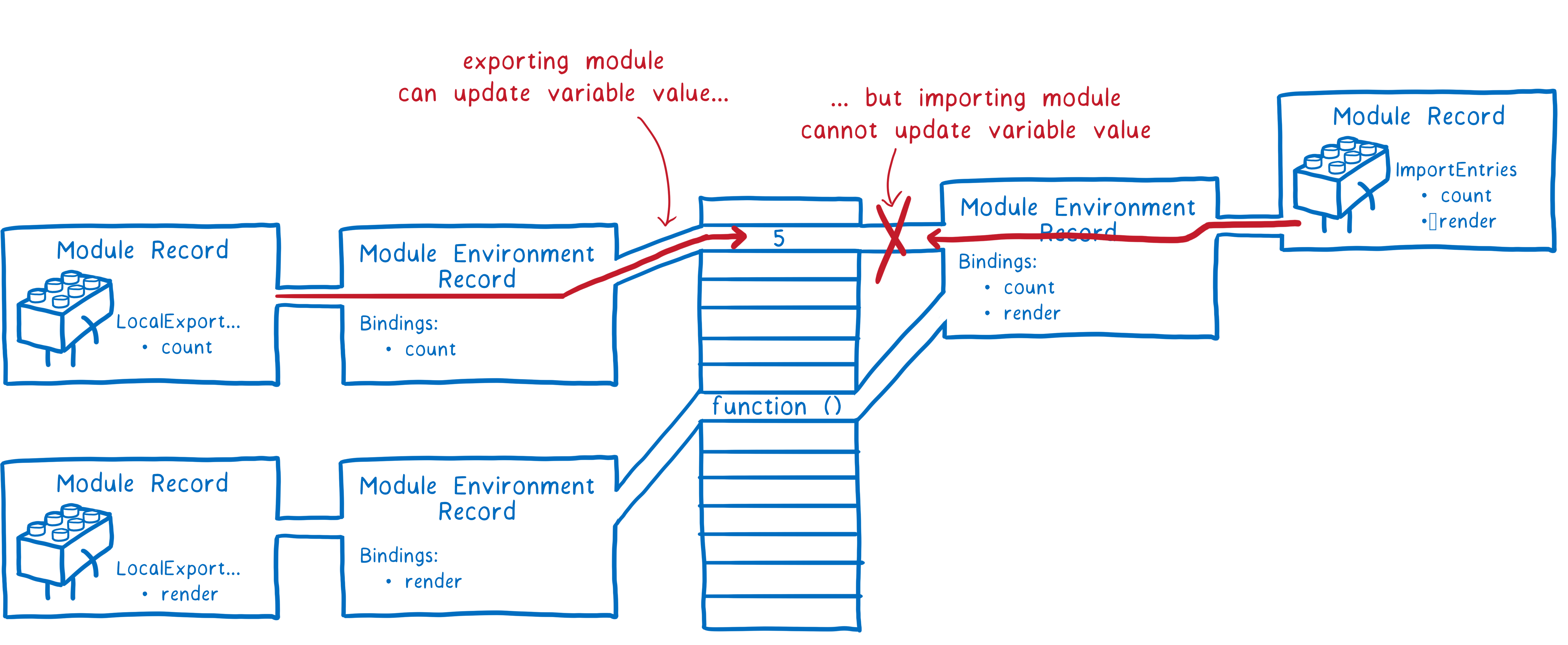
阶段一:构建(Construction )。根据地址查找 js 文件,并且下载,将其解析成模块记录(Module Record)。
阶段二:实例化(Instantiation)。对模块记录进行实例化,并且分配内存空间,解析模块的导入和导出语句,把模块指向对应的内存地址。
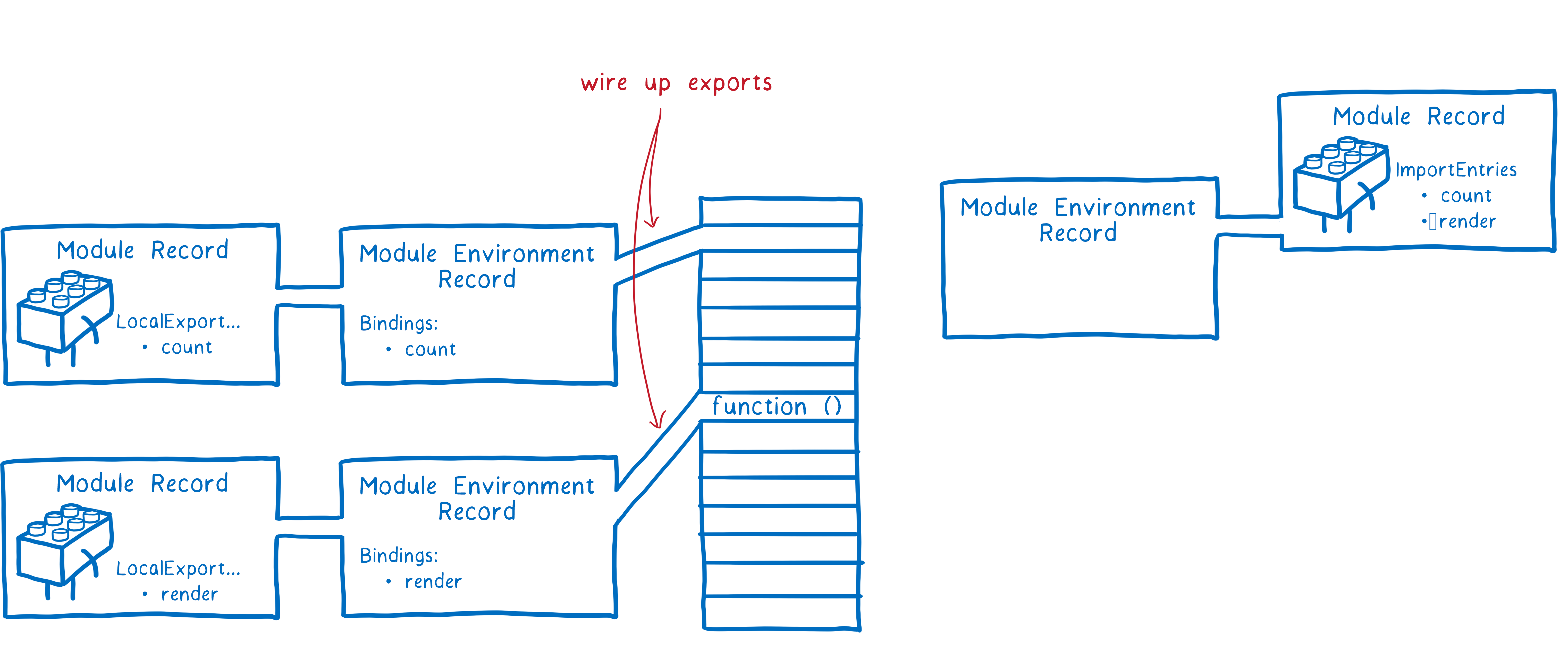
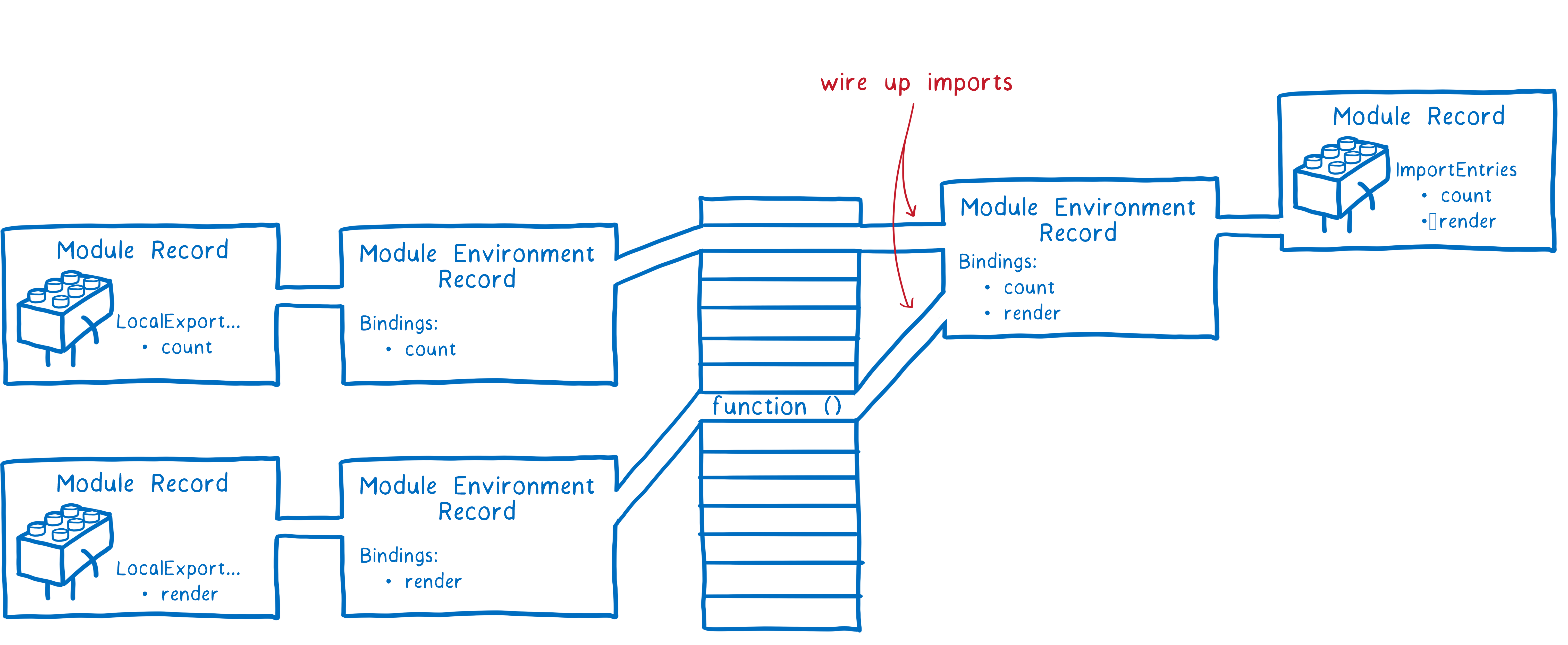
在这一步的最后,我们使得所有的模块实例导出/导入的变量的内存地址链接起来了。
阶段三:运行(Evaluation)。运行代码,计算值,并且将值填充到内存地址中。
四、其他
1. ES6 模块与 CommonJS 模块的差异
- CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用,且是只读。
- CommonJS 模块是运行时加载,ES6 模块是编译时输出接口。
- CommonJS 模块的
require()是同步加载模块,ES6 模块的 import 命令是异步加载,有一个独立的模块依赖的解析阶段。
2. Node.js 的模块加载方法
1)使用不同模块规范
从 Node.js v13.2 版本开始,Node.js 已经默认打开了 ES6 模块支持。
Node.js 要求 ES6 模块采用 .mjs 后缀文件名。
如果不希望将后缀名改成 .mjs,可以在项目的 package.json 文件中,指定 type 字段为 module。
如果这时还要使用 CommonJS 模块,那么需要将 CommonJS 脚本的后缀名都改成 .cjs。如果没有 type 字段,或者 type 字段为 commonjs,则 .js 脚本会被解释成 CommonJS 模块。
结论:.mjs 文件总是以 ES6 模块加载,.cjs 文件总是以 CommonJS 模块加载,.js 文件的加载取决于 package.json 里面 type 字段的设置。
2)模块入口文件
[1] package.json 的 main 字段
package.json 文件有两个字段可以指定模块的入口文件:main 和 exports。比较简单的模块,可以只使用 main 字段,指定模块加载的入口文件。
// ./node_modules/es-module-package/package.json
{
"type": "module",
"main": "./src/index.js"
}上面代码指定项目的入口脚本为 ./src/index.js,它的格式为 ES6 模块。
然后,import 命令就可以加载这个模块。
// ./my-app.mjs
import { something } from 'es-module-package';
// 实际加载的是 ./node_modules/es-module-package/src/index.js[2] package.json 的 exports 字段
exports 字段的优先级高于 main 字段。
(1) 子目录别名
package.json 文件的 exports 字段可以指定脚本或子目录的别名。
// ./node_modules/es-module-package/package.json
{
"exports": {
"./submodule": "./src/submodule.js"
}
}上面的代码指定 src/submodule.js 别名为 submodule,然后就可以从别名加载这个文件。
import submodule from 'es-module-package/submodule';
// 加载 ./node_modules/es-module-package/src/submodule.js下面是子目录别名的例子。
// ./node_modules/es-module-package/package.json
{
"exports": {
"./features/": "./src/features/"
}
}
import feature from 'es-module-package/features/x.js';
// 加载 ./node_modules/es-module-package/src/features/x.js如果没有指定别名,就不能用“模块+脚本名”这种形式加载脚本。
// 报错
import submodule from 'es-module-package/private-module.js';
// 不报错
import submodule from './node_modules/es-module-package/private-module.js';(2) main 的别名
exports 字段的别名如果是 .,就代表模块的主入口,优先级高于 main 字段,并且可以直接简写成 exports 字段的值。
{
"exports": {
".": "./main.js"
}
}
// 等同于
{
"exports": "./main.js"
}由于 exports 字段只有支持 ES6 的 Node.js 才认识,所以可以搭配 main字段,来兼容旧版本的 Node.js。
{
"main": "./main-legacy.cjs",
"exports": {
".": "./main-modern.cjs"
}
}上面代码中,老版本的 Node.js (不支持 ES6 模块)的入口文件是 main-legacy.cjs,新版本的 Node.js 的入口文件是 main-modern.cjs。
(3)条件加载
利用 . 这个别名,可以为 ES6 模块和 CommonJS 指定不同的入口。
{
"type": "module",
"exports": {
".": {
"require": "./main.cjs",
"default": "./main.js"
}
}
}上面代码中,别名 . 的 require 条件指定 require() 命令的入口文件(即 CommonJS 的入口),default 条件指定其他情况的入口(即 ES6 的入口)。
上面的写法可以简写如下。
{
"exports": {
"require": "./main.cjs",
"default": "./main.js"
}
}注意,如果同时还有其他别名,就不能采用简写,否则会报错。
{
// 报错
"exports": {
"./feature": "./lib/feature.js",
"require": "./main.cjs",
"default": "./main.js"
}
}3)互相加载
[1] CommonJS 模块加载 ES6 模块
CommonJS 的 require() 命令不能加载 ES6 模块,会报错,只能使用 import() 这个方法加载。
(async () => {
await import('./my-app.mjs');
})();require() 不支持 ES6 模块的一个原因是,它是同步加载。ES6 模块是异步。
[2] ES6 模块加载 CommonJS 模块
ES6 模块的 import 命令可以加载 CommonJS 模块,但是只能整体加载,不能只加载单一的输出项。
// 正确
import packageMain from 'commonjs-package';
// 报错
import { method } from 'commonjs-package';[3] 同时支持两种格式的模块
可以把文件的后缀名改为 .mjs,或者将它放在一个子目录,再在这个子目录里面放一个单独的 package.json 文件,指明 { type: "module" }。
另一种做法是在 package.json 文件的 exports 字段,指明两种格式模块各自的加载入口。
"exports":{
"require": "./index.js",
"import": "./esm/wrapper.js"
}上面代码指定 require() 和 import,加载该模块会自动切换到不一样的入口文件。
3. 循环加载
1)CommonJS 模块的循环加载
CommonJS 的一个模块,就是一个脚本文件。require命令第一次加载该脚本,就会执行整个脚本,然后在内存生成一个对象。
{
id: '...', // 模块名
exports: { ... }, // 模块输出的各个接口
loaded: true, // 该模块的脚本是否执行完毕
...
}以后需要用到这个模块的时候,就会到 exports 属性上面取值。即使再次执行 require 命令,也不会再次执行该模块,而是到缓存之中取值。
第三章:包管理工具
一、NPM 概述
1. 介绍
NPM 全称 Node Package Manager(Node 的包管理器)是一个应用程序。
可以从官网 https://www.npmjs.com 搜索包以及查看包的信息。
包是什么?
Node.js 的包基本遵循 CommonJS 规范,将一组相关的模块组合在一起,形成一个完整的工具。
2. 作用
通过 NPM 可以对 Node 的工具包进行搜索、下载、安装、删除、上传。借助别人写好的包,可以让开发更加方便。
常见的使用场景有以下 3 种:
- 允许用户从 NPM 服务器下载别人编写的第三方包到本地使用。
- 允许用户从 NPM 服务器下载并安装别人编写的命令行程序到本地使用。
- 允许用户将自己编写的包上传到 NPM 服务器供别人使用。
3. 安装
安装 nodejs 时会自动安装 npm,无需额外安装。
二、NPM 常用操作命令
1. 查看 npm 的版本
npm -v2. 初始化
项目中没有 package.json,我们需要进行初始化,创建 package.json 文件。
npm init
# 以下命令可以快速初始化
npm init --yes
npm init -y常见的配置文件
- package.json:这是一个项目的主要配置文件,它包含了许多重要的信息和配置选项:
- name:项目的名称。
- version:项目的版本号。
- description:项目的描述。
- main:项目的入口文件。
- scripts:用于运行的脚本命令,例如 npm start / npm run start,npm test 等。
- private:如果设置为 true,npm 会阻止发布这个包。
- dependencies:项目运行所需的依赖包及其版本号。
- devDependencies:项目开发所需的依赖包及其版本号。
- peerDependencies:项目的同级依赖,通常用于库或插件的开发。
- optionalDependencies:项目的可选依赖。这些依赖在安装时如果失败,npm 不会报错,而是会继续安装其他的包。
- .npmrc:这个文件可以用来配置 npm 的行为。它是一个简单的键值对格式的文件。
- npm-shrinkwrap.json 和 package-lock.json:这两个文件都是用来锁定项目依赖的版本的。它们会列出项目的所有依赖,包括直接依赖和间接依赖,以及每个依赖的精确版本号。这样可以确保在不同的环境中安装相同的依赖。npm-shrinkwrap.json 和 package-lock.json 的主要区别在于,前者会被发布到 npm,而后者不会。
.npmrc 配置文件
.npmrc 文件是一个存储 npm 配置的文件,它可以存在于四个位置:
- 全局配置文件:位于 $PREFIX/etc/npmrc,其中 $PREFIX 是 Node.js 安装的位置。
- 用户配置文件:位于 ~/.npmrc,在用户的主目录下。
- 项目配置文件:位于项目根目录下的 .npmrc 文件。
- npm 包的配置文件:位于 npm 包目录下的 .npmrc 文件。
.npmrc 文件中的配置项优先级由低到高依次是:全局配置 < 用户配置 < 项目配置 < npm 包的配置。
其中一些常见的配置项包括:
- registry:设置 npm 的注册表 URL,例如
registry=https://registry.npmjs.org/。 - proxy 和 https-proxy:设置 npm 的代理服务器,例如
proxy=http://127.0.0.1:7890/和https-proxy=https://xxx.xxx:7890/。 - prefix:设置全局安装的路径,例如
prefix=/usr/local。 - save-exact:设置是否在安装包时保存精确的版本号,例如
save-exact=true。 - email:设置用户的 email,用于发布包,例如
email=user@example.com。 - always-auth:设置是否总是需要认证,例如
always-auth=true。
package-lock.json 配置文件
package-lock.json 文件是在你运行 npm install 命令时自动生成的一个文件(如果这个文件不存在的话)。这个文件记录了安装的每一个包的确切版本号,包括所有的依赖包。这意味着,不管何时你或者其他人在同一个项目中运行 npm install,都会得到完全相同版本的依赖。
这个文件的主要目的是为了确保项目的依赖的一致性,使得所有的开发者和 CI/CD 系统都能使用完全相同版本的依赖,从而避免了"在我机器上可以运行"这样的问题。
package-lock.json 文件的主要部分包括:
- name:项目的名称。
- version:项目的版本号。
- lockfileVersion:lock 文件的版本号,npm 会根据这个版本号来确定如何读取和写入这个文件。
- requires:为 true 表示这个项目需要并使用依赖项的版本锁定功能。
- packages:项目的所有依赖,包括直接依赖和间接依赖。每一个依赖都包含了版本号、来源、完整性校验等信息。
通常不需要手动编辑 package-lock.json 文件,npm 会自动管理这个文件。当添加、更新或者删除依赖时,npm 会相应地更新这个文件。
限制包的版本范围:
~:匹配最近的小版本。例如,~1.2.3会匹配所有1.2.x版本,但会忽略1.3.0。- ^:匹配最近的大版本。例如,
^1.2.3会匹配任何1.x.x版本,包括1.3.0,但会忽略2.0.0。 - *:匹配任何版本。
>、<、>=、<=:分别匹配大于、小于、大于等于、小于等于指定版本的版本。-:指定一个版本范围。例如,1.0.0 - 1.2.0。- ||:组合多个版本范围。例如,
< 1.0.0 || > 2.0.0。
3. 搜索包
npm search 包名
npm s 包名该命令使用频率不高,一般在搜索包的时候,会到 https://www.npmjs.com 搜索。
4. 安装包
npm install 包名
npm i 包名
# 安装并在 package.json 中保存包的信息 (dependencies 属性,表示生成依赖)
npm install 包名 --save
npm install 包名 -S
# 安装并在 package.json 中保存包的信息 (devDependencies 属性,表示开发依赖)
npm install babel --save-dev
npm install babel -D注意:6 以及以上版本的 npm,安装包时会自动保存在 dependencies 中,可以不用写 --save。
当我们拿到某个项目后,一般都需要执行 npm i 来安所有依赖。
包安装完成之后文件夹下会增加一个文件夹和一个文件:
- node_modules 文件夹:存放下载的包。
- package-lock.json:包的锁文件,用来锁定包的版本。
1)生产依赖与开发依赖
生产环境与开发环境
开发环境是程序员 专门用来写代码 的环境,一般是指程序员的电脑,开发环境的项目一般 只能程序员自己访问。
生产环境是项目 代码正式运行 的环境,一般是指正式的服务器电脑,生产环境的项目一般 每个客户都可以访问。
总结:开发依赖是只在开发阶段使用的依赖包,而生产依赖是开发阶段和最终上线运行阶段都用到的依赖包。
我们可以在安装时设置选项来区分依赖的类型,目前分为两类:
| 类型 | 命令 | 补充 |
|---|---|---|
| 生产依赖 | npm i -S 包名 npm i --save 包名 | -S 等效于 --save,-S 是默认选项 包信息保存在 package.json 中 dependencies 属性 |
| 开发依赖 | npm i -D 包名 npm i --save-dev 包名 | -D 等效于 --save-dev 包信息保存在 package.json 中 devDependencies 属性 |
2)全局安装
我们可以执行安装选项 -g 进行全局安装。
npm i -g nodemon全局安装完成之后就可以在命令行的任何位置运行 nodemon 命令。
该命令的作用是自动重启 node 应用程序。
说明:
① 全局安装的命令不受工作目录位置影响。
② 可以通过 npm root -g 可以查看全局安装包的位置。
③ 安装在
C:/Users/你的用户名/AppData/Roaming/npm位置。
3)安装指定版本的包
项目中可能会遇到版本不匹配的情况,有时就需要安装指定版本的包,可以使用下面的命令。
# 格式
npm i <包名@版本号>
# 示例
npm i jquery@1.11.25. 删除依赖
项目中可能需要删除某些不需要的包,可以使用下面的命令。
npm uninstall 包名
npm uninstall -g 包名 # 删除全局安装的包
npm remove 包名 # remove 是 uninstall 的别名
npm remove -g 包名6. 配置命令别名
通过配置命令别名可以更简单的执行命令。步骤如下:
配置 package.json 中的 scripts 属性。
{
......
"scripts": {
"server": "node server.js",
"start": "node index.js",
},
......
}配置完成之后,可以使用别名执行命令。
npm run server
npm run start不过 start 别名比较特别,使用时可以省略 run。
npm start补充说明:
npm start 是项目中常用的一个命令,一般用来启动项目。
npm run 有自动向上级目录查找的特性,跟 require 函数也一样。
对于陌生的项目,我们可以通过查看 scripts 属性来参考项目的一些操作。
7. 更新包
npm update 包名
npm update -g 包名 # 更新全局安装的包
npm outdated # 查看当前本地安装的包哪些需要更新
npm outdated -g # 查看当前全局安装的包哪些需要更新注意:更新本地安装的包,会受到 pakeage.json 中版本设置的约束;更新全局安装的包会直接更新到最新版。
8. 安装项目依赖
如果项目中已经存在 package.json,可以根据 package.json 中的依赖声明,安装工具包。
npm install
npm i
npm install --production # 只安装生产环境依赖
npm i --production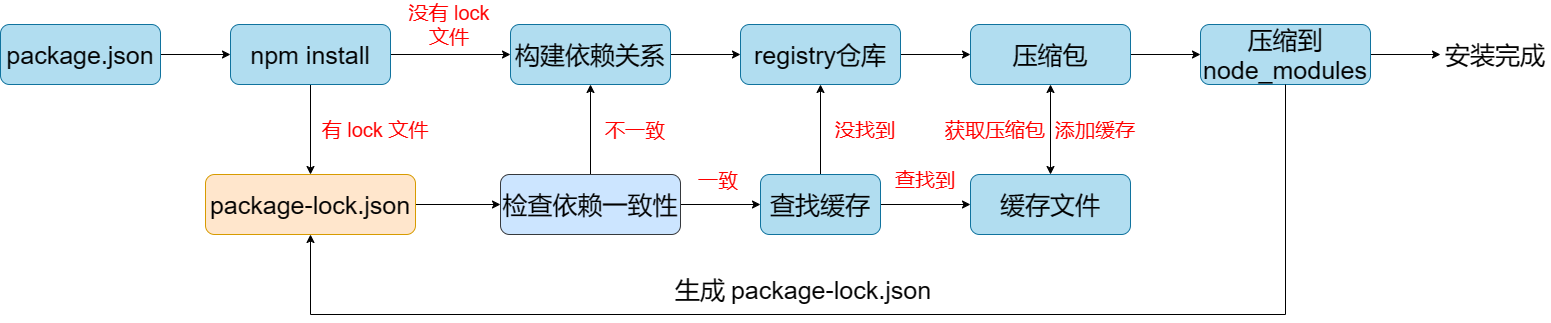
9. 缓存管理
npm config get cache # 查看缓存路径
npm config set cache "D:\dev\cache\npm-cache" # 设置新的缓存目录
npm cache clean --force # force 表示强制清除缓存
npm cache verify # 查看缓存大小和内容10. 管理发布包
1)创建与发布
可以将自己开发的工具包发布到 npm 服务上,方便自己和其他开发者使用,操作步骤如下:
① 创建文件夹,并创建文件 index.js, 在文件中声明函数,使用 module.exports 暴露。
② npm 初始化工具包,package.json 填写包的信息(包的名字是唯一的)。
③ 注册账号:https://www.npmjs.com/signup
④ 激活账号(一定要激活账号)。
⑤ 修改为官方的官方镜像(命令行中运行 nrm use npm)。
⑥ 命令行下 npm login 填写相关用户信息。
⑦ 命令行下 npm publish 提交包 👌
2)更新包
后续可以对自己发布的包进行更新,操作步骤如下:
① 更新包中的代码。
② 测试代码是否可用。
③ 修改 package.json 中的版本号。
④ 发布更新 npm publish。
3)删除包
执行如下命令删除包。
npm unpublish --force删除包需要满足一定的条件,参见:https://docs.npmjs.com/policies/unpublish
三、cnpm
1. 介绍
cnpm 是一个淘宝构建的 npmjs.com 的完整镜像,也称为『淘宝镜像』。网址:https://npmmirror.com
cnpm 服务部署在国内阿里云服务器上,可以提高包的下载速度。
官方也提供了一个全局工具包 cnpm,操作命令与 npm 大体相同。
2. 安装
方式一:全局安装 cnpm 命令,安装完成后使用 cnpm 命令代替 npm 命令。
npm install -g cnpm --registry=https://registry.npmmirror.com方式二(Linux):通过添加 npm 参数 alias 一个新命令,安装完成后使用 cnpm 命令代替 npm 命令。
alias cnpm="npm --registry=https://registry.npmmirror.com \
--cache=$HOME/.npm/.cache/cnpm \
--disturl=https://npmmirror.com/mirrors/node \
--userconfig=$HOME/.cnpmrc"方式三:把官方镜像地址修改为淘宝镜像地址,修改后继续使用 npm 命令。
# 设置为淘宝镜像
npm config set registry https://registry.npmmirror.com
# 验证配置
npm config get registry
# 如果想改回官方镜像
npm config set registry https://registry.npmjs.com3. 操作命令
| 功能 | 命令 |
|---|---|
| 初始化 | cnpm init |
| 安装包 | cnpm install 包名 cnpm i 包名 cnpm i -S 包名 cnpm i -D 包名 cnpm i -g 包名 |
| 安装项目依赖 | cnpm i |
| 删除 | cnpm r 包名 |
4. nrm 🛠
使用 nrm: NPM registry manager 配置管理 npm 的镜像地址。
1)安装 nrm
npm i -g nrm2)修改镜像
nrm use taobao
nrm use npm3)检查是否配置成功
npm config list检查 registry 地址是否为 https://registry.npmmirror.com,如果是则表明成功。
虽然 cnpm 可以提高速度,但是 npm 也可以通过淘宝镜像进行加速,所以 npm 的使用率还是高于 cnpm。
四、yarn
1. 介绍
yarn 是由 Facebook 在 2016 年推出的新的 Javascript 包管理工具。官方网址:https://yarnpkg.com
2. 特点
官方宣称的一些特点。
- 速度超快:yarn 缓存了每个下载过的包,所以再次使用时无需重复下载。同时利用并行下载以最大化资源利用率,因此安装速度更快。
- 超级安全:在执行代码之前,yarn 会通过算法校验每个安装包的完整性。
- 超级可靠:使用详细、简洁的锁文件格式(npm 的锁文件为 package-lock.json;yarn 的锁文件为 yarn.lock)和明确的安装算法,yarn 能够保证在不同系统上无差异的工作。
3. 安装
npm 安装 yarn
npm i -g yarnmsi 安装包安装
https://classic.yarnpkg.com/en/docs/install#windows-stable
提前需要安装 Node.js。
4. yarn 常用命令
| NPM | Yarn |
|---|---|
| npm --version | yarn --version |
| npm init / npm init -y | yarn init / yarn init -y |
| npm i | yarn install 是 yarn 命令的默认行为。所以,无论你是运行 yarn 还是 yarn install,都会安装项目的所有依赖项。 |
| npm run <别名> | yarn <别名> |
| npm install | yarn install |
| npm install [package]@[version] | yarn add [package]@[version] |
| npm install --save [package] | yarn add [package] |
| npm install [--save-dev/-D] [package] | yarn add [package] [--dev/-D] |
| npm i -g [package] | yarn global add [package] |
| npm rebuild | yarn install --force |
| npm uninstall [package] | yarn remove [package] |
| npm uninstall --save [package] | yarn remove [package] |
| npm uninstall --save-dev [package] | yarn remove [package] |
| npm uninstall --save-optional [package] | yarn remove [package] |
| npm uninstall -g [package] | yarn global remove [package] |
| npm cache clean | yarn cache clean |
| rm-rf node_modules && npm install | yarn upgrade |
思考题:全局安装的包在任意位置找不到命令,怎么办?
配置 path 环境。yarn 全局安装包的位置在 C:/Users/你的用户名/AppData/Local/Yarn/bin,可以通过 yarn global bin 来查看。
5. yarn 配置淘宝镜像
方法一:可以通过如下命令配置淘宝镜像。
yarn config set registry https://registry.npmmirror.com可以通过 yarn config list 查看 yarn 的配置项。yarn config get registry 查看当前 yarn 源。
方法二:跟 npm 与 cnpm 的关系一样,可以为 yarn 设置国内的淘宝镜像,提升安装的速度。
npm install cyarn -g --registry "https://registry.npmmirror.com"配置后,只需将 yarn 改为 cyarn 使用即可。
五、pnpm
1. 什么是 pnpm?
pnpm 是一个 Node.js 包管理器,类似于 npm 和 yarn。它的主要特点是高效的包存储方式。当多个项目依赖同一个包版本时,pnpm 不会像 npm 或 yarn 那样为每个项目复制一份包,而是将包存储在一个共享的地方,并通过硬链接或符号链接的方式引用它。这种方式可以节省大量的磁盘空间,同时也可以加快安装速度。
一句话概括:pnpm 代表 performant(高性能的)npm。
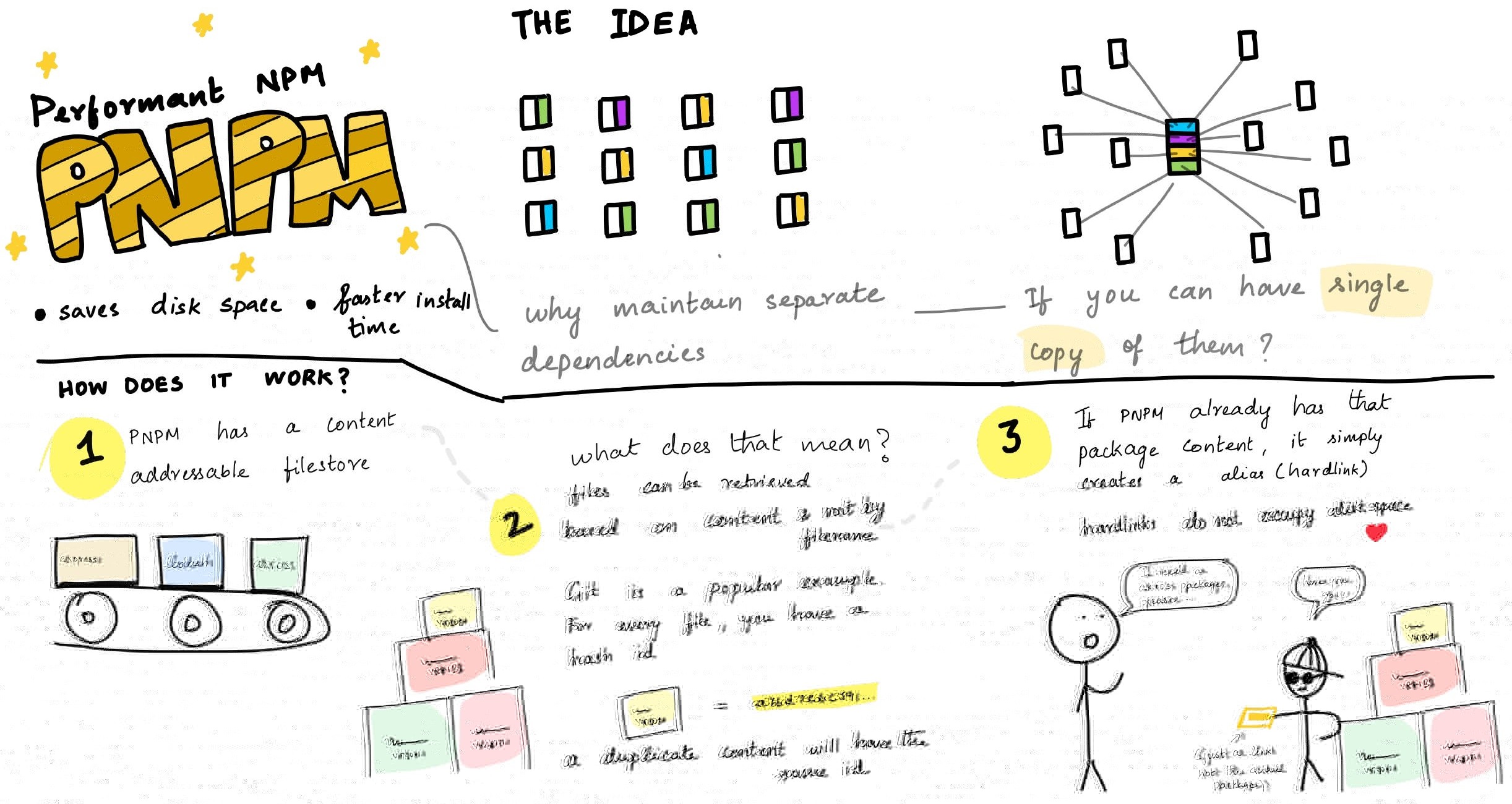
pnpm 还有其他一些特点,例如:
- 它严格遵守 node_modules 的结构:如果一个包没有在项目的 package.json 文件中声明为依赖,那么它就不会出现在 node_modules 目录中。
- 它有一个强大的命令行界面,可以很方便地进行包的安装、卸载、更新和查询。
- 它支持 npm 的所有命令和特性,包括 npm scripts、npm shrinkwrap、npm audit 等。
pnpm 的这些特性使得它在一些场景中比 npm 和 yarn 更有优势。
2. 原理
1)百宝锦囊
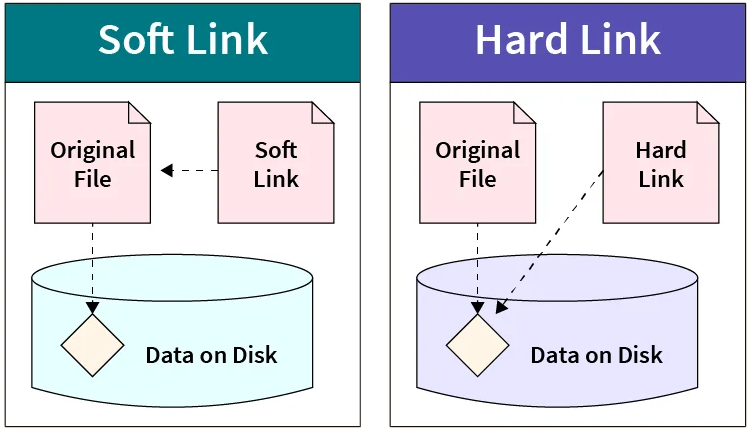
[1] 硬链接和软链接
硬链接(hard link)是电脑文件系统中的多个文件平等地共享同一个文件存储单元。删除一个文件名字后,还可以用其它名字继续访问该文件。
符号链接 / 软链接(soft link、Symbolic link)是一类特殊的文件。其包含有一条以绝对路径或者相对路径的形式指向其它文件或者目录的引用。
[2] 非扁平的 node_modules
参考这篇文章:Why should we use pnpm? by @ZoltanKochan
NPM 版本 3 之前:
node_modules
└─ foo
├─ index.js
├─ package.json
└─ node_modules
└─ bar
├─ index.js
└─ package.json问题:① 包经常创建太深的依赖关系树;② 当在不同的依赖项中需要包时,它们被复制粘贴了几次。
为了解决这些问题,npm 重新考虑了 node_modules 结构并提出了扁平化。 有了 npm@3:
node_modules
├─ foo
| ├─ index.js
| └─ package.json
└─ bar
├─ index.js
└─ package.json
pnpm 原理,一句话就是:pnpm 创建非扁平的 node_modules 目录。
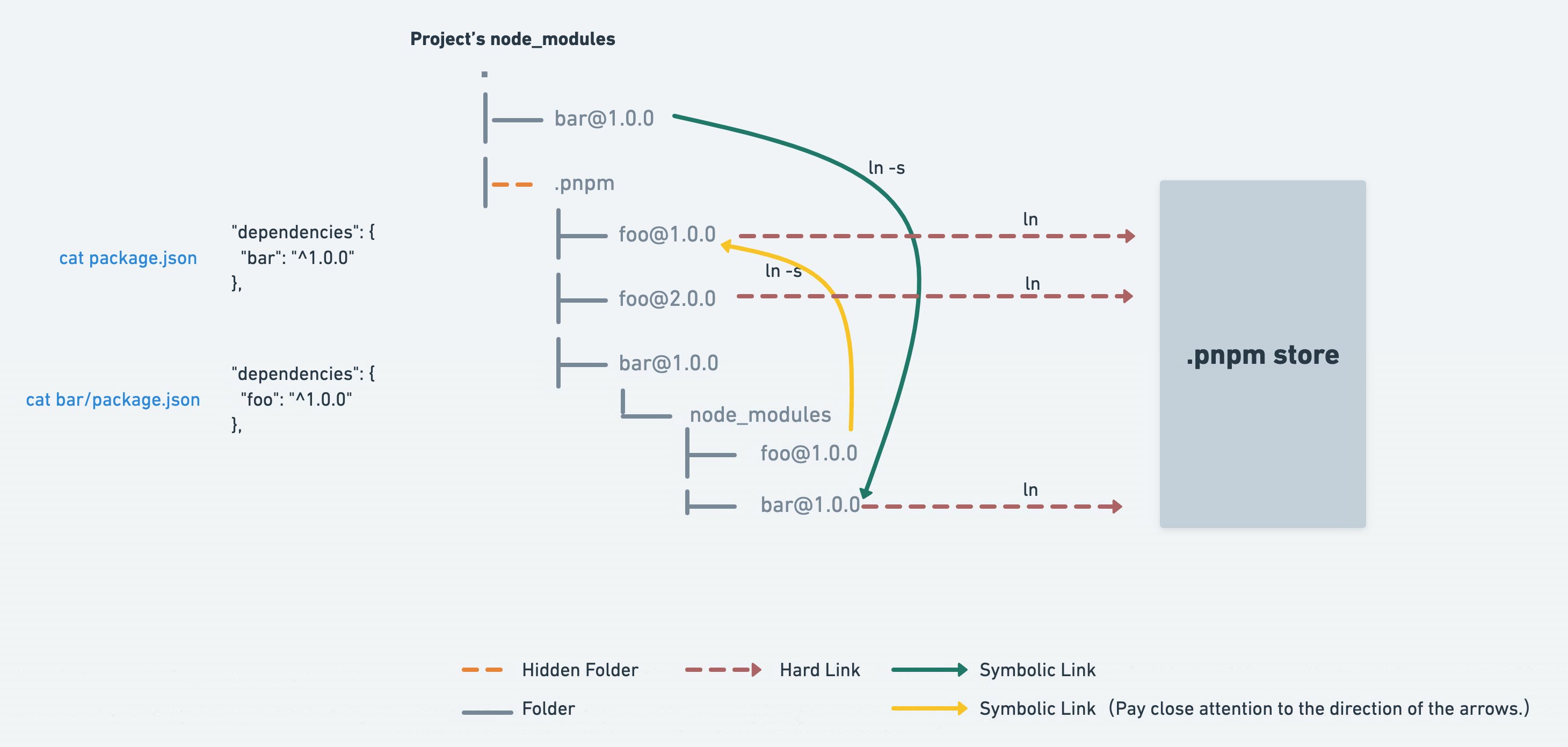
首先,pnpm 会将所有的包硬链接到 .pnpm 文件夹下的对应子文件夹中。例如,如果你安装了 bar@1.0.0,它依赖于 foo@1.0.0,那么 pnpm 会将这两个包硬链接到 .pnpm 文件夹下的 foo@1.0.0/node_modules/bar 和 bar@1.0.0/node_modules/foo。
然后,pnpm 会创建符号链接来构建依赖关系。例如,foo 会被符号链接到 bar@1.0.0/node_modules 文件夹,表示 bar 依赖于 foo。
最后,对于直接依赖的包,例如 bar,pnpm 会将其符号链接到根 node_modules 文件夹。
这种方式的好处是,每个包只能访问到它依赖的包,而不能访问到其他不相关的包。这样可以避免一些由于错误访问了不应该访问的包而导致的问题。==> 很好的解决了分身问题和幽灵依赖问题。
2)实战开始
准备
先创建一个项目,使用 pnpm 管理包。之后添加依赖。
Get-ExecutionPolicy
set-ExecutionPolicy remoteSigned
pnpm --version
pnpm init
pnpm add -D nodemon开始分析依赖结构
第一条关系
PS C:\Users\ddf> Get-Item "D:\VSCode\111\node_modules\nodemon" | Select-Object FullName, Target, LinkType
FullName Target LinkType
-------- ------ --------
D:\VSCode\111\node_modules\nodemon {D:\VSCode\111\node_modules\.pnpm\nodemon@3.1.10\node_modules\nodemon\} Junction发现关系:D:\VSCode\111\node_modules\nodemon --> D:\VSCode\111\node_modules\.pnpm\nodemon@3.1.10\node_modules\nodemon\
PS C:\Users\ddf> Get-Item "D:\VSCode\111\node_modules\.pnpm\nodemon@3.1.10\node_modules\nodemon\package.json" | Select-Object FullName, Target, LinkType
FullName Target LinkType
-------- ------ --------
D:\VSCode\111\node_modules\.pnpm\nodemon@3.1.10\node_modules\nodemon\package.json {D:\pnpm-store\store\v3\files\55\9d44404a74f7d9a7d7441eb6f4d740d4b7b158447c301ccf9f9c6320d7133034c4fb5e8c7cd99a943e35393e3d061633dc246972896a21de42ebdc85a28191} HardLinkcmd /c "fsutil hardlink list D:\VSCode\111\node_modules\.pnpm\nodemon@3.1.10\node_modules\nodemon\package.json"
\pnpm-store\store\v3\files\55\9d44404a74f7d9a7d7441eb6f4d740d4b7b158447c301ccf9f9c6320d7133034c4fb5e8c7cd99a943e35393e3d061633dc246972896a21de42ebdc85a28191
\VSCode\111\node_modules\.pnpm\nodemon@3.1.10\node_modules\nodemon\package.json发现 D:\VSCode\111\node_modules\.pnpm\nodemon@3.1.10\node_modules\nodemon 下的文件其实硬链接到 pnpm 存储库中。
第二条关系
PS C:\Users\ddf> Get-Item "D:\VSCode\111\node_modules\.pnpm\nodemon@3.1.10\node_modules\chokidar" | Select-Object FullName, Target, LinkType
FullName Target LinkType
-------- ------ --------
D:\VSCode\111\node_modules\.pnpm\nodemon@3.1.10\node_modules\chokidar {D:\VSCode\111\node_modules\.pnpm\chokidar@3.6.0\node_modules\chokidar\} Junction发现关系:D:\VSCode\111\node_modules\.pnpm\nodemon@3.1.10\node_modules\chokidar --> D:\VSCode\111\node_modules\.pnpm\chokidar@3.6.0\node_modules\chokidar\
PS C:\Users\ddf> Get-Item "D:\VSCode\111\node_modules\.pnpm\chokidar@3.6.0\node_modules\chokidar\package.json" | Select-Object FullName, Target, LinkType
FullName Target LinkType
-------- ------ --------
D:\VSCode\111\node_modules\.pnpm\chokidar@3.6.0\node_modules\chokidar\package.json {D:\pnpm-store\store\v3\files\c4\ed6d522c3412ca4c100064e9fef549b1c7a86b4127cd2fb98468b4d505f6c79bc0b9bb539ca375f354fc75ebbe200d5f813845a36f54f5986e3e63ea97ea3a} HardLink发现 D:\VSCode\111\node_modules\.pnpm\chokidar@3.6.0\node_modules\chokidar 下的文件其实硬链接到 pnpm 存储库中。
3. 安装
官网提供了很多种方式来安装 pnpm:https://pnpm.io/zh/installation
1️⃣ 通过 npm 安装
npm install -g pnpm2️⃣ 设置 $XDG_DATA_HOME 环境变量。意思是 pnpm 所产生的文件存放在哪里(包括存储库)。
3️⃣ 其他环境变量:$XDG_CONFIG_HOME、$XDG_CACHE_HOME、$XDG_STATE_HOME
4. 使用
1)管理依赖常用命令
| npm 命令 | pnpm 等价命令 |
|---|---|
| npm install | pnpm install |
| npm i [package] | pnpm add [package] |
| npm i -D [package] | pnpm add -D [package] |
| npm i -g [package] | pnpm add -g [package] |
| npm uninstall [package] | pnpm remove [package] |
| npm run [cmd] | pnpm [cmd] |
2)管理 pnpm 文件
[1] 配置文件路径
配置文件为 INI (全局) 和 YAML (本地) 格式。
本地配置文件位于项目的根目录中,名为 pnpm-workspace.yaml。
全局配置文件位于以下位置之一:
- 如果设置了
$XDG_CONFIG_HOME环境变量,则为$XDG_CONFIG_HOME/pnpm/rc。 - 在 Windows 上:
~/AppData/Local/pnpm/config/rc。 - 在 macOS 上:
~/Library/preferences/pnpm/rc。 - 在 Linux上:
~/.config/pnpm/rc。
[2] storeDir
所有包被保存在磁盘上的位置。默认值:
- 如果设置了
$PNPM_HOME环境变量,则为$PNPM_HOME/pnpm/rc。 - 如果设置了
$XDG_DATA_HOME环境变量,则为$XDG_DATA_HOME/pnpm/store。 - 在 Windows 上:
~/AppData/Local/pnpm/store。 - 在 macOS 上:
~/Library/pnpm/global。 - 在 Linux 上:
~/.local/share/pnpm/store。
建议以后前端项目都创建在与 storeDir 相同的磁盘上。原因参见:存储路径已指定。
[3] globalDir
指定储存全局依赖的目录。默认值:
- 如果设置了
$XDG_DATA_HOME环境变量,则为$XDG_DATA_HOME/pnpm/store。 - 在 Windows 上:
~/AppData/Local/pnpm/store。 - 在 macOS 上:
~/Library/pnpm/global。 - 在 Linux 上:
~/.local/share/pnpm/global。
官方文档地址:globaldir
[4] globalBinDir
允许设置全局安装包的 bin 文件的目标目录。默认值:
- 如果设置了
$XDG_DATA_HOME环境变量,则为$XDG_DATA_HOME/pnpm。 - 在 Windows 上:
~/AppData/Local/pnpm。 - 在 macOS 上:
~/Library/pnpm。 - 在 Linux 上:
~/.local/share/pnpm。
[5] stateDir
pnpm 创建的当前仅由更新检查器使用的 pnpm-state.json 文件的目录。默认值:
- 如果设置了
$XDG_STATE_HOME环境变量,则为$XDG_STATE_HOME/pnpm。 - 在 Windows 上:
~/AppData/Local/pnpm-state。 - 在 macOS 上:
~/.pnpm-state。 - 在 Linux 上:
~/.local/share/pnpm。
[6] cacheDir
缓存的位置(软件包元数据和 dlx)。默认值:
- 如果设置了
$XDG_CACHE_HOME环境变量,则为$XDG_CACHE_HOME/pnpm。 - 在 Windows 上:
~/AppData/Local/pnpm-cache。 - 在 macOS 上:
~/Library/Caches/pnpm。 - 在 Linux 上:
~/.cache/pnpm。
[7] registry
设置使用的源。
推荐 pnpm + nrm。
3)管理配置文件
可以使用下面的命令来设置全局存储的位置:
# --------------------------------------------------------------------------
# 设置下载包所使用的源
pnpm config set registry https://registry.npmmirror.com/
# --------------------------------------------------------------------------
# 指定全局安装包的安装位置
pnpm config set store-dir "D:/pnpm-store/store"
# 指定 pnpm 存储所有包的共享存储位置。
pnpm config set global-dir "D:/pnpm-store/global"
# 设置全局安装包的可执行文件 (binaries) 的存储位置。
pnpm set global-bin-dir "D:/pnpm-store/global/bin"
# 包元数据缓存的位置。
pnpm config set cache-dir "D:/pnpm-store/pnpm-cache"
# 其他 (不建议)
# pnpm 创建的当前仅由更新检查器使用的 pnpm-state.json 文件的目录。
pnpm config set state-dir "D:/pnpm-store/pnpm-state"
# 设置虚拟存储路径
pnpm config set virtual-store-dir "D:/pnpm-store/virtual-store"
# 设置日志文件目录
pnpm config set logs-dir "D:/pnpm-store/logs"可以通过运行以下命令来获取当前活跃的 pnpm 存储目录:
pnpm store path # 返回激活的存储目录的路径
# 或者
pnpm config get store-dir
# 查看所有配置
pnpm config list从 store 中删除当前未被引用的包来释放 store 的空间:
pnpm store prune4)pnpm root
打印有效的存放模块的目录。
配置项:
--global, -g
打印全局软件包的模块目录。
pnpm root -g 获取全局包的安装目录。在 PNPM 中,全局包是指那些通过 pnpm install -g 命令安装的包。
第四章:内置模块
一、路径
path 模块用于处理路径。模块的常用方法如下:
| 方法名 | 描述 |
|---|---|
| join() | 用于拼接参数提供的路径。 该方法的主要用途在于,会正确使用当前系统的路径分隔符,Unix 系统是" /",Windows 系统是"\"。 |
| resolv() | 会解析当前运行命令所在目录的绝对路径 + 参数提供的路径 (常用)。path.resolv(__dirname, './座右铭.txt'); |
| isAbsolute() | 判断参数是否是绝对路径。 |
| dirname() | 返回路径中目录的部分 。 |
| basename() | 返回路径中的最后一部分,文件名部分。 |
| extname() | 返回路径中文件的后缀名。 |
| sep | 获取操作系统的路径分隔符。 |
| parse() | 解析路径并返回对象。 |
二、文件系统
1. Buffer(缓冲器)
1)概念
Buffer 是一个类似于数组的对象,用于表示固定长度的字节序列。
Buffer 本质是一段内存空间,专门用来处理二进制数据。

2)特点
a. Buffer 大小固定且无法调整。
b. Buffer 性能较好,可以直接对计算机内存进行操作。
c. 每个元素的大小为 1 字节(byte)。

3)使用
[1] 创建 Buffer
Node.js 中创建 Buffer 的方式主要如下几种:
Buffer.allocjavascript// 创建了一个长度为 10 字节的 Buffer,相当于申请了 10 字节的内存空间,每个字节的值为 0 let buf_1 = Buffer.alloc(10) //=>结果为<Buffer 00 00 00 00 00 00 00 00 00 00>Buffer.allocUnsafejavascript// 创建了一个长度为 10 字节的 Buffer,buffer 中可能存在旧数据,可能会影响执行结果,所以叫 unsafe ,但是效率比 alloc 高 let buf_2 = Buffer.allocUnsafe(10)Buffer.fromjavascript// 通过字符串创建 Buffer let buf_3 = Buffer.from('hello') // 通过数组创建 Buffer let buf_4 = Buffer.from([105, 108, 111, 118, 101, 121, 111, 117])
[2] Buffer 与字符串的转化
可以借助 toString 方法将 Buffer 转为字符串。
let buf_4 = Buffer.from([105, 108, 111, 118, 101, 121, 111, 117])
console.log(buf_4.toString()) //=>iloveyou注意:toString 默认是按照 utf-8 编码方式进行转换的。
[3] Buffer 的读写
Buffer 可以直接通过 [] 的方式对数据进行处理。
let buf_3 = Buffer.from('hello')
// 读取
console.log(buf_3[1]) //=>101
// 修改
buf_3[1] = 97
// 查看字符串结果
console.log(buf_3.toString()) //=>hallo注意:
- Buffer 实例的每个元素只有 1 个字节,能表示的最大数字是 255,溢出的高位数据会舍弃。
- 一个 UTF-8 的中文字符大多数情况都是占 3 个字节。
2. 文件操作 / fs 模块
1)文件读取
| 方法 | 说明 |
|---|---|
| readFile | 异步读取 |
| readFileSync | 同步读取 |
| createReadStream | 流式读取 |
[1] readFile 异步读取
语法:fs.readFile(path[, options], callback)
参数说明
path:文件路径。
如果 path 是相对路径,那么会解析当前运行命令所在目录的绝对路径 + 相对路径。
options:选项配置。
callback:回调函数。
返回值:undefined
代码示例:
/*
data 是 Buffer 对象
如果没有错误, error 是 null
*/
fs.readFile('./座右铭.txt', (error,data) =>{
if(err) throw err
console.log(data.toString())
})
/*
data 是 string 对象
*/
fs.readFile('./座右铭.txt', 'uft-8', (error,data) =>{
if(err) throw err
console.log(data)
})[2] readFileSync 同步读取
语法:fs.readFileSync(path[, options])
参数说明
path:文件路径。
options:选项配置。
返回值:string | Buffer
Node.js 中的磁盘操作是由其他线程完成的,结果的处理有两种模式:
- 同步处理 JavaScript 主线程会等待其线程的执行结果,然后再继续执行主线程的代码。
效率较低- 异步处理 JavaScript 主线程不会等待其线程的执行结果,直接执行后续的主线程代码。
效率较好
代码示例:
/*
如果路径不存在, 会抛出异常
*/
let data = fs.readFileSync('./座右铭.txt') // 返回 Buffer
let data = fs.readFileSync('./座右铭.txt', 'utf-8') // 返回 string[3] createReadStream 流式读取
语法:fs.createReadStream(path[, options])
参数说明
path:文件路径
options:选项配置(可选)
返回值:Object
代码示例:
// 创建读取流对象
let rs = fs.createReadStream('./观书有感.txt')
// 每次取出 64k 数据后执行一次 data 回调
// 绑定一个 data 事件 chunk 块儿 大块儿
re.on('data', chunk =>{
console.log(chunk)
console.log(chunk.length)
})
// 读取完毕后,执行 end 回调 (可选事件)
re.on('end', () =>{
console.log('读取完毕')
})2)文件写入
| 方法 | 说明 |
|---|---|
| writeFile | 异步写入 |
| writeFileSync | 同步写入 |
| appendFile / appendFileSync | 追加写入 |
| createWriteStream | 流式写入 |
[1] writeFile 异步写入
语法:fs.writeFile(file, data [, options], callback)
参数说明
file:文件名。
data:待写入的数据(字符串或 Buffer)。
options:选项设置(可选)。
callback:写入回调。
返回值:undefined
示例代码:
// require 是 Node.js 环境中的 '全局' 变量,用来导入模块
const fs = require('fs')
// 将 [三人行,必有我师焉。] 写入到当前文件夹下的 [座右铭.txt] 文件中
fs.writeFile('./座右铭.txt', '三人行,必有我师焉。', err =>{
// 如果写入失败,则回调函数调用时,会传入错误对象,如写入成功,会传入 null
if(err){
console.log(err)
return
}
console.log('写入成功')
})[2] writeFileSync 同步写入
语法:fs.writeFileSync(file, data[, options])
参数与 fs.writeFile 大体一致,只是没有 callback 参数。
返回值:undefined
示例代码:
try{
fs.writeFileSync('./座右铭.txt', '三人行,必有我师焉。')
}catch(e){
console.log(e)
}[3] appendFile / appendFileSync 追加写入
appendFile 作用是在文件尾部追加内容,appendFile 语法与 writeFile 语法完全相同。
语法:
fs.appendFile(file, data[, options], callback)
fs.appendFileSync(file, data[, options])
返回值:二者都为 undefined
示例代码:
fs.append('./座右铭.txt', '则其善者而从之,其不善者而改之。', err =>{
if(err) throw err
console.log('追加成功')
})
fs.appendFileSync('./座右铭.txt','/r/n温故而知新,可以为师矣')[4] createWriteStream 流式写入
语法:fs.createWriteStream(path [, options])
参数说明
path:文件路径
options:选项配置(可选)
返回值:Object
代码示例:
let ws = fs.createWriteStream('./观书有感.txt')
// 写入数据到流
ws.write('半亩方塘一鉴开/r/n')
ws.write('天光云影共徘徊/r/n')
ws.write('问渠那得清如许/r/n')
ws.write('为有源头活水来/r/n')
// 关闭写入流,表明已没有数据要被写入可写流
ws.end()程序打开一个文件是需要消耗资源的,流式写入可以减少打开关闭文件的次数。
流式写入方式适用于大文件写入或者频繁写入的场景,writeFile 适合于写入频率较低的场景。
3)文件移动与重命名
使用 rename 或 renameSync 来移动或重命名文件或文件夹。
语法
fs.rename(oldPath, newPath, callback)
fs.renameSync(oldPath, newPath)
参数说明
oldPath:文件当前的路径
newPath:文件新的路径
callback:操作后的回调
代码示例:
fs.rename('./观书有感.txt', './论语/观书有感.txt', err => {
if(err) throw err
console.log('移动完成')
})
fs.renameSync('./座右铭.txt', './论语/.我的座右铭.txt')注:如果还是移动到当前路径,但是修改了名字,就是重命名了。
4)文件删除
使用 unlink 或 unlinkSync 来删除文件。
语法
fs.unlink(path, callback)
fs.unlinkSync(path)
参数说明
path:文件路径
callback:操作后的回调
代码示例:
const fs = require('fs')
fs.unlink('./test.txt', err =>{
if(err) throw err
console.log('删除成功')
})
fs.unlinkSync('./test2.txt')
// 调用 rm 方法
fs.rm('./论语.txt', err => {
if (err) {
console.log('删除失败')
return
}
console.log('删除成功')
})在 Node.js 的 fs(文件系统)模块中,fs.unlink、fs.unlinkSync 和 fs.rm 都是用于删除文件的函数。它们的主要区别在于处理方式和支持的 Node.js 版本。
1)fs.unlink(path, callback) 和 fs.unlinkSync(path):这两个函数是早期版本的 Node.js 用来删除文件的方法。fs.unlink 是异步的,它在删除文件后调用回调函数。fs.unlinkSync 是同步的,它会阻塞 Node.js 进程直到文件被删除。这两个函数只能用于删除文件,不能删除目录。
2)fs.rm(path, options, callback) 和 fs.rmSync(path, options):这两个函数在 Node.js v14.14.0 中引入,用于替代 fs.unlink、fs.unlinkSync、fs.rmdir 和 fs.rmdirSync。fs.rm 和 fs.rmSync 不仅可以删除文件,还可以删除目录,并且支持更多的选项,如递归删除、强制删除等。
3. 文件夹 / 目录操作
借助 Node.js 的能力,可以对文件夹进行创建、读取、删除等操作。
| 方法 | 说明 |
|---|---|
| mkdir / mkdirSync | 创建文件夹 |
| readdir / readdirSync | 读取文件夹 |
| rmdir / rmdirSync | 删除文件夹 |
1)mkdir 创建文件夹
使用 mkdir 或 mkdirSync 来创建文件夹。
语法
fs.mkdir(path[, options], callback)
fs.mkdirSync(path[, options])
参数说明
path:文件夹路径
options:选项配置(可选)
callback:操作后的回调
示例代码:
// 异步创建文件夹
fs.mkdir('./page', err =>{
if(err) throw err
console.log('创建成功')
})
// 递归异步创建
fs.mkdir('./1/2/3', {recursive: true}, err =>{
if(err) throw err
console.log('递归创建成功')
})
// 递归同步创建文件夹
fs.mkdirSync('./x/y/z', {recursive: true})2)readdir 读取文件夹
使用 readdir 或 readdirSync 来读取文件夹。
语法
fs.readdir(path [, options], callback)
fs.readdirSync(path [, options])
参数说明
path:文件夹路径
options:选项配置(可选)
callback:操作后的回调
示例代码:
// 异步读取
fs.readdir('./论语', (err, data) => {
if(err) throw err
console.log(data)
})
// 同步读取
let data = fs.readdirSync('./论语')
console.log(data)3)rmdir 删除文件夹
废弃 API。
使用 rmdir 或 rmdirSync 来删除文件夹。
语法
fs.rmdir(path[, options], callback)
fs.redirSync(path[, options])
参数说明
path 文件夹路径
options 选项配置(可选)
callback 操作后的回调
示例代码:
// 异步删除文件夹 rm remove 移除
fs.rmdir('./page', err => {
if(err) throw err
console.log('删除成功')
})
//异步递归删除文件夹 (不推荐)
//=>DeprecationWarning: In future versions of Node.js, fs.rmdir(path, { recursive: true }) will be removed. Use fs.rm(path, { recursive: true }) instead
fs.rmdir('./1', {recursive: true}, err => {
if(err){
console.log(err)
return
}
console.log('递归删除')
})
//同步递归删除文件夹
fs.rmdirSync('./x', {recursive: true})
// 建议使用
fs.rm('./a', { recursive: true }, err => {
if (err) {
console.log(err)
return
}
console.log('删除成功')
})4. 查看资源状态
使用 stat 或 statSync 来查看资源的详细信息。
语法
fs.stat(path[, options], callback)
fs.statSync(path[, options])
参数说明
path:文件夹路径
options:选项配置(可选)
callback:操作后的回调
示例代码:
// 异步获取状态
// stat 是 status 缩写
fs.stat('/data.txt', (err, data) =>{
if(err) throw err
console.log(data)
})
// 同步获取状态
let data = fs.statSync('./data.txt')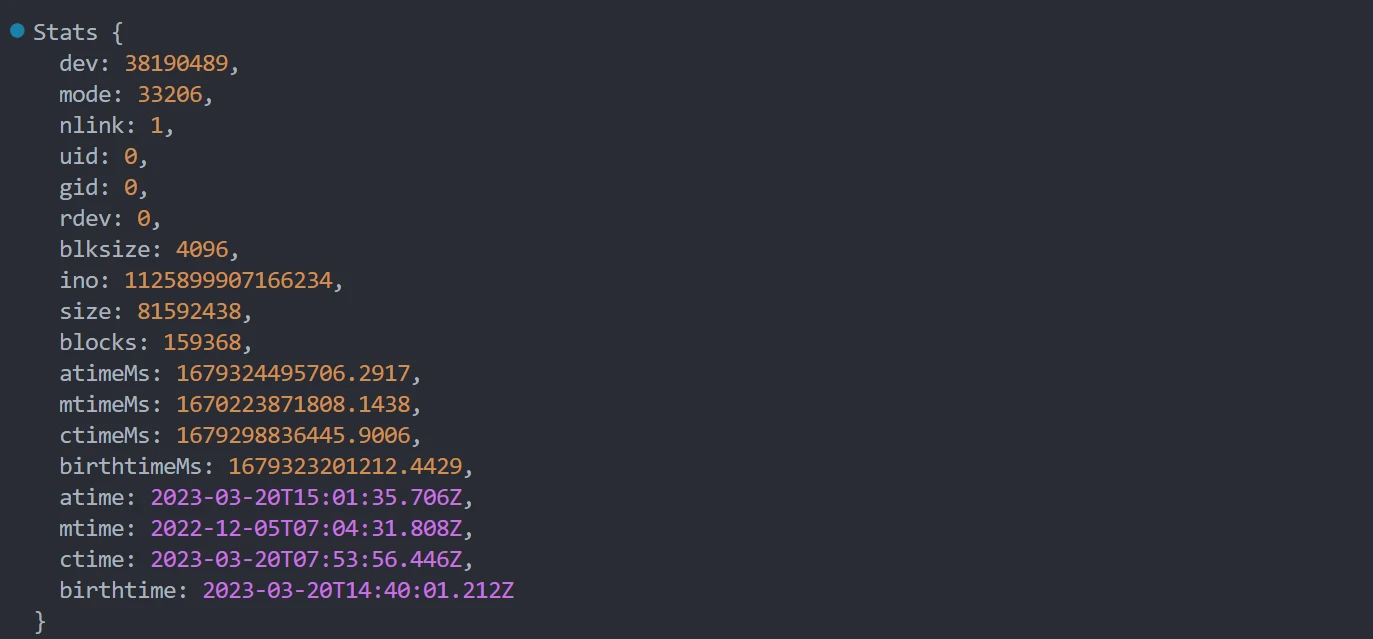
结果值对象结构:
- dev:设备标识符,表示文件所在的设备。
- mode:文件模式,表示文件的权限和类型。这个值是一个十进制数,可以通过位运算解析出具体的权限(例如,读、写、执行权限)。
- nlink:硬链接的数量,表示指向该文件的硬链接数。
- uid:文件所有者的用户 ID。
- gid:文件所有者的组 ID。
- rdev:如果文件是字符设备或块设备,则表示设备 ID(通常为 0)。
- blksize:文件系统的块大小,通常用于 I/O 操作的最优块大小。
- ino:文件的索引节点号(inode number),文件系统内部的唯一标识符。
size: 文件的大小(以字节为单位)。
blocks:文件所占用的块数(以 512 字节为单位)。
atimeMs:文件上次访问时间的时间戳(以毫秒为单位)。
mtimeMs:文件上次修改时间的时间戳(以毫秒为单位)。
ctimeMs:文件状态(元数据信息)最后更改时间的时间戳(以毫秒为单位)。
birthtimeMs:文件创建时间的时间戳(以毫秒为单位)。
atime:文件上次访问时间(以日期时间格式表示)。
mtime:文件上次修改时间(以日期时间格式表示)。
ctime:文件状态最后更改时间(以日期时间格式表示)。
birthtime:文件创建时间(以日期时间格式表示)。
类型判断方法:
- isFile:检测是否为文件
isDirectory:检测是否为文件夹
....
5. 判断文件或目录是否存在
// 异步方式 判断文件或目录是否存下
fs.access(file02, err => {
if (err) {
console.log('文件不存在!');
} else {
console.log('文件存在!');
}
});
// 同步方式
try {
fs.accessSync(file02);
console.log('文件存在!');
} catch {
console.log('文件不存在!');
}三、URL 模块
url 模块用于 URL 处理与解析。
new URL(input[, base])WHATWG URL API (新 API) 。在全局对象上,使用不需要引入。若非要引用
console.log(URL === require('node:url').URL);input:如果为相对网址,需要 base 参数。否则不需要,即使写了,也会忽略。
base:input 不是绝对的网址,需要提供此参数。
const url = require("url");返回 url 对象,来处理 url。【过期】
const url = require("url");
const str = "http://www.baidu.com/a/b/index.html?id=12&type=1#one";
// 用法一:返回一个url信息组成的对象 (过时)
url.parse(str);
// 用法二:实例化得到一个url信息组成的对象
const u = new url.URL(str);
// 解析之后得到的对象如下:
URL {
href: 'http://www.baidu.com/a/b/index.html?id=12&type=1#one',
origin: 'http://www.baidu.com',
protocol: 'http:',
username: '',
password: '',
host: 'www.baidu.com',
hostname: 'www.baidu.com',
port: '',
pathname: '/a/b/index.html',
search: '?id=12&type=1',
searchParams: URLSearchParams { 'id' => '12', 'type' => '1' },
hash: '#one'
}
// 用法二:可以进一步简单
const urlObject = new URL(urlString);
console.log(urlObject.hostname); // 'example.com'
console.log(urlObject.port); // '8080'四、querystring
用于解析和格式化网址查询字符串的实用工具。
querystring.parse(str[, sep[, eq[, options]]])querystring.stringify(obj[, sep[, eq[, options]]])
const querystring = require('querystring');
querystring.parse('foo=bar&abc=xyz&abc=123')
// 解析之后得到的对象如下:
/*
{
"foo": "bar",
"abc": ["xyz", "123"]
}
*/
querystring.stringify({ foo: 'bar', baz: ['qux', 'quux'], corge: '' }); // 'foo=bar&baz=qux&baz=quux&corge='
querystring.stringify({ foo: 'bar', baz: 'qux' }, ';', ':'); // 'foo:bar;baz:qux'五、stream
基本用不上,自行学习。
第五章:HTTP 服务
一、快速入门
http 是 Node 中处理 HTTP 协议的模块,可以用来创建 HTTP 服务。
// 引入 http 模块
const http = require('http');
// 创建 http 服务程序
// http.createServer 需要一个回调函数作为参数,当有客户端像该服务请求的时候,回调函数会触发
// 回调函数被调用的时候,会接收到两个参数,分别是请求对象和响应对象
const server = http.createServer((request, response) => {
console.log('接收到客户端请求!');
// 设置响应头,解决中文乱码
response.setHeader('content-type','text/html;charset=utf-8');
// 设置响应内容并且结束响应
response.end('hello nodejs');
});
// 开启服务,需要设置端口号和回调函数
// 服务成功开启之后,回调函数会被触发
server.listen(8090, () => {
console.log('http 启动成功!端口号 8090');
});- server 是创建的 HTTP 服务的实例。http.Server
- request 是对请求报文的封装对象。http.ClientRequest
- response 是对响应的封装对象。http.ServerResponse
如果端口被其他程序占用,可以使用资源监视器找到占用端口的程序,还可以命令行中运行命令 netstat -ano | findstr 端口号 来获取占用端口的程序的进程 ID。然后使用任务管理器关闭对应的程序。
二、request 方法
| 含义 | 语法 | 重点掌握 |
|---|---|---|
| 请求方法 | request.method | ***** |
| 请求路径 | request.url | ***** |
| 请求版本 | request.httpVersion | |
| 请求头 | request.headers request.headers.请求头名字 | ***** |
| 获取客户端 IP 地址 | request.socket.remoteAddress | |
| 请求体 | request.on('data', function(chunk){}) request.on('end', function(){}) | |
| URL 路径 | require('url').parse(request.url).pathname | ***** |
| URL 查询字符串 | require('url').parse(request.url, true).query | ***** |
提醒
① request.url 只能获取路径以及查询字符串,无法获取 URL 中的域名以及协议的内容。
② request.headers 将请求信息转化成一个对象,并将属性名都转化成了『小写』。
③ request 本质上是一个可读流对象。
1. 提取 http 报文中 url 的路径与查询字符串
旧方法:
// 导入 http 模块
const http = require('http')
// 1. 导入 url 模块
const url = require('url')
// 创建服务对象
const server = http.createServer((request, response) => {
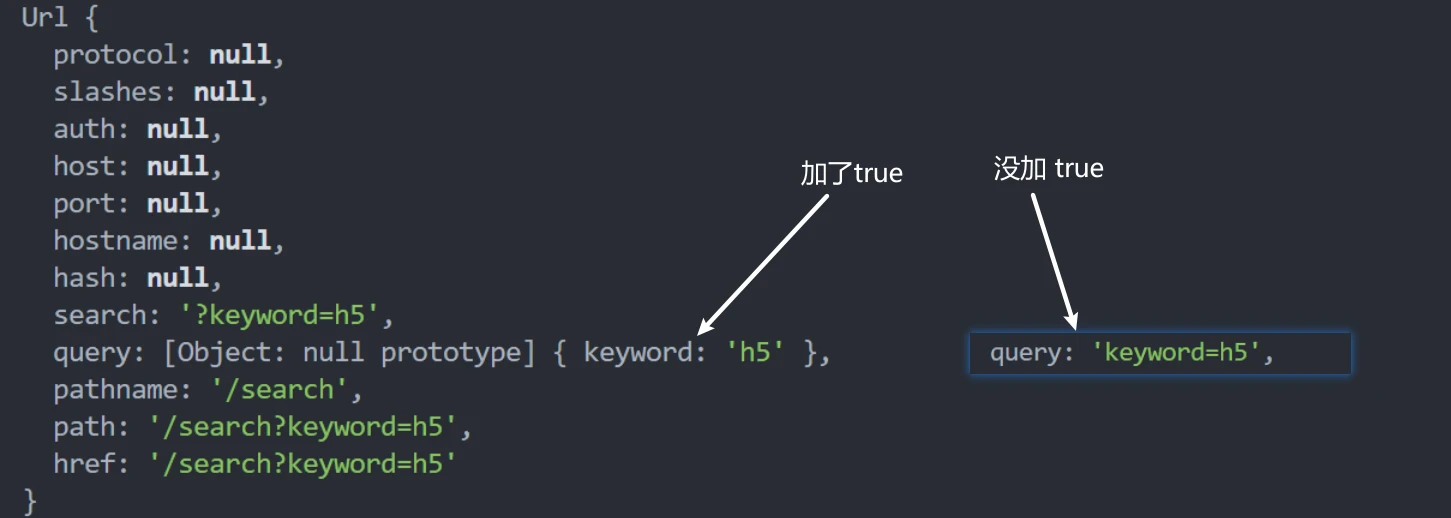
// 2. 解析 request.url
console.log(request.url) // =>/search?keyword=h5
// 使用 parse 解析 request.url 的内容
// true 将 query 属性将会设置为一个对象
let res = url.parse(request.url, true)
console.log(res) // 如下图所示,为一个对象
// 路径
let pathname = res.pathname
// 查询字符串
let keyword = res.query.keyword
console.log(keyword) //=>h5
response.end('url')
})
// 监听端口,启动服务
server.listen(9000, () => {
console.log('服务已经启动...')
})
新方法:
// 导入 http 模块
const http = require('http')
// 创建服务对象
const server = http.createServer((request, response) => {
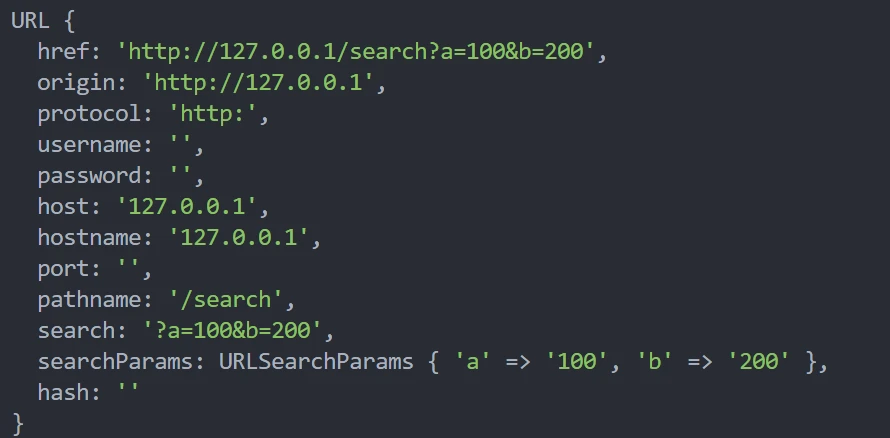
// 实例化 url 对象
let url = new URL(request.url, 'http://127.0.0.1')
console.log(url) // => 如图所示,为一个对象
// 输出路径
console.log(url.pathname) // => /search
// 输出 keyword 查询字符串
console.log(url.searchParams.get('a')) // => 100
response.end('url new')
})
// 监听端口,启动服务
server.listen(9000, () => {
console.log('服务已经启动...')
})
2. 提取 http 报文的请求体
// 1. 导入 http 模块
const http = require('http')
// 2. 创建服务对象
const server = http.createServer((request, response) => {
// 2.1 声明一个变量
let body = ''
// 2.2 绑定 data 事件
request.on('data', chunk => {
// chunk 是 buffer,如果执行加法运算,会把 buffer 转换为字符串
body += chunk
})
// 2.3 绑定 end 事件
request.on('end', () => {
console.log(body) // 'username=111&password=111'
// 响应
response.end('Hello Http') // 设置响应体
})
})
// 3. 监听端口,启动服务
server.listen(9000, () => {
console.log('服务已经启动...')
})三、response 方法
| 作用 | 语法 |
|---|---|
| 设置响应状态码 | response.statusCode |
| 设置响应状态描述 | response.statusMessage (用的非常少) |
| 设置响应头信息 | response.setHeader('头名', '头值') (可以自定义) |
| 设置响应体 | response.write('xxx') response.end('xxx') |
设置响应行和响应头:
// 1.设置响应状态码
response.statusCode = 203
// 2.响应状态的描述
response.statusMessage = 'i love you'
// 3.响应头
response.setHeader('content-type', 'text/html;charset=utf-8')
// 自定义响应头
response.setHeader('myHeader', 'test test')
// 设置多个同名的响应头
response.setHeader('test', ['a', 'b', 'c'])设置响应体:
// write 和 end 的两种使用情况
// 1.write 和 end 的结合使用,响应体相对分散
response.write('xx');
response.write('xx');
response.write('xx');
response.end(); // 每一个请求,在处理的时候必须要执行 end 方法的
// 2.单独使用 end 方法,响应体相对集中
// end 方法的参数可以是字符串也可以是 Buffer
response.end('xxx'); // 有且只能有一个同时设置响应行和响应头
// 同时设置 响应状态码、设置响应状态描述、响应头
response.writeHead(响应状态码, '响应状态描述', {
'响应头名字' : '响应头内容',
'响应头名字' : '响应头内容',
'响应头名字' : '响应头内容'
...
})第六章:express
一、介绍
express 是一个基于 Node.js 平台的极简、灵活的 WEB 应用开发框架。官方网址:https://expressjs.com
简单来说,express 是一个封装好的工具包,封装了很多功能,便于我们开发 WEB 应用(HTTP 服务)。
二、快速入门
1. express 下载
express 本身是一个 npm 包,所以可以通过 npm 安装。
npm i express2. express 初体验
1)创建 JS 文件,键入如下代码。
// 1. 导入 express
const express = require('express');
// 2. 创建应用对象
const app = express();
// 3. 创建路由规则
app.get('/home', (req, res) => {
res.end('hello express server');
});
// 4. 监听端口 启动服务
app.listen(3000, () =>{
console.log('服务已经启动, 端口监听为 3000...');
});2)命令行下执行该脚本。
node <文件名>
# 或者
nodemon <文件名>3)然后在浏览器就可以访问 http://127.0.0.1:3000/home 👌
三、路由
1. 什么是路由
官方定义:路由确定了应用程序如何响应客户端对特定端点的请求。
2. 路由的使用
一个路由的组成有请求方法,路径和回调函数组成。
express 中提供了一系列方法,可以很方便的使用路由,使用格式如下:
app.<method>(path,callback)示例代码:
// 导入 express
const express = require('express');
// 创建应用对象
const app = express();
// 创建 get 路由
app.get('/home', (req, res) => {
res.send('网站首页');
});
// 首页路由
app.get('/', (req,res) => {
res.send('我才是真正的首页');
});
// 创建 post 路由
app.post('/login', (req, res) => {
res.send('登录成功');
});
// 匹配所有的请求方法
app.all('/search', (req, res) => {
res.send('为您找到相关结果约 100,000,000 个');
});
// 自定义 404 路由
app.all("*", (req, res) => {
res.send('<h1>404 Not Found</h1>')
});
// 监听端口,启动服务
app.listen(3000, () =>{
console.log('服务已经启动, 端口监听为 3000');
});路由回调支持多个(记得指定 next 参数):
/*
app.get('/abc/a', func1, func2, func3); // 参数为多个函数列表
app.get('/abc/a', [func1, func2, func3]); // 参数为多个函数数组
app.get('/abc/a', [func1, func2, func3], func1, func2, func3); // 参数为多个函数数组、列表混合
*/
app.get('/example/b', function (req, res, next) {
console.log('response will be sent by the next function ...');
next();
}, function (req, res) {
res.send('Hello from B!');
});四、请求与响应设置
1. 获取请求参数
express 框架封装了一些 API 来方便获取请求报文中的数据,并且兼容原生 HTTP 模块的获取方式。
// 导入 express
const express = require('express');
// 创建应用对象
const app = express();
// 获取请求的路由规则
app.get('/request', (req, res) => {
// 1. 获取报文的方式与原生 HTTP 获取方式是兼容的
console.log(req.method);
console.log(req.url);
console.log(req.httpVersion);
console.log(req.headers);
// 2. express 独有的获取报文的方式
// 获取路径
console.log(req.path)
// 获取 IP
console.log(req.ip)
// 获取查询字符串
console.log(req.query); // 『相对重要』对象形式返回所有的查询字符串
// 获取指定的请求头
console.log(req.get('host'));
res.send('请求报文的获取');
});
// 启动服务
app.listen(3000, () => {
console.log('启动成功....')
})2. 获取路由参数
路由参数指的是 URL 路径中的参数(数据)。
// 路径中的参数信息代替查询字符串
// 匹配 /news/20342323/a12.shtml
app.get('/news/:date/:id.shtml', (req, res) => {
res.send('新闻详情, 新闻 id 为' + req.params.id);
});3. 获取请求体数据
request.body 必须经过 body-parser 中间件的处理才能获取到请求体数据解析成的对象,否则只能得到 undefined。
第一步:安装
npm i body-parser # 处理请求体第二步:导入 body-parser 包
const bodyParser = require('body-parser');第三步:获取中间件函数
// 处理 querystring 格式的请求体
let urlParser = bodyParser.urlencoded({extended:false})); // extended 为真,允许解析复杂的对象和数组
// 处理 JSON 格式的请求体
let jsonParser = bodyParser.json();
/*
urlParser 和 jsonParser 需要引入到中间件
第一种:全局 app.use(urlParser)、app.use(jsonParser)
第二种:某个路由单独使用。路由第二个参数传入
*/第四步:设置路由中间件,然后使用 request.body 来获取请求体数据
app.post('/login', urlParser, (request, response)=>{
// 获取请求体数据
//console.log(request.body);
// 用户名
console.log(request.body.username);
// 密码
console.log(request.body.userpass);
response.send('获取请求体数据');
});获取到的请求体数据:
[Object: null prototype] { username: 'admin', userpass: '123456' }现在已经可以抛弃 body-parser 模块,因为 Express 自从 4.16.0 版本开始,内置了 body 解析。使用方法:
const express = require('express');
const app = express();
// 使用内置的 express.json 和 express.urlencoded 中间件函数来解析请求主体
app.use(express.json()); // 用于解析 application/json 请求主体
app.use(express.urlencoded({ extended: true })); // 用于解析 application/x-www-form-urlencoded 请求主体
// 一个简单的 POST 路由,响应任何发送到'/data'的 POST 请求
app.post('/data', (req, res) => {
console.log(req.body); // 请求主体会被解析并输出到控制台
res.send('Data received');
});
app.listen(3000, () => {
console.log('Server is running on port 3000');
});4. 响应设置
express 框架封装了一些 API 来方便给客户端响应数据,并且兼容原生 HTTP 模块的获取方式。
// 获取请求的路由规则
app.get("/response", (req, res) => {
// 1. express 中设置响应的方式兼容 HTTP 模块的方式
res.statusCode = 404;
res.statusMessage = 'xxx';
res.setHeader('abc','xyz');
res.write('响应体');
res.end('xxx');
// 2. express 的响应方【支持链式调用】
res.status(500); //设置响应状态码
res.set('xxx','yyy'); //设置响应头
res.send('中文响应不乱码'); //设置响应体
// 连贯操作
res.status(404).set('xxx','yyy').send('你好朋友')
// 3. 其他响应
res.redirect('http://baidu.com') // 重定向
res.download('./package.json'); // 下载响应
res.json({name:'jack',age:18}); // 响应 JSON
res.sendFile(__dirname + '/home.html') // 响应文件内容
});五、中间件
1. 概念
1)什么是中间件
Express 是一个自身功能极简,完全是由路由和中间件构成一个的 web 开发框架。从本质上来说,一个 Express 应用就是在调用各种中间件。
中间件(Middleware)本质是一个回调函数。中间件函数可以像路由回调一样访问请求对象(request), 响应对象(response)。
之前学习的路由方法的回调函数本质上也是中间件。
直接点:中间件就是过滤器。
2)作用
中间件的作用就是使用函数封装公共操作,简化代码。
3)类型
全局中间件:每一个请求到达服务端之后都会执行全局中间件函数。
路由中间件:特定请求执行。
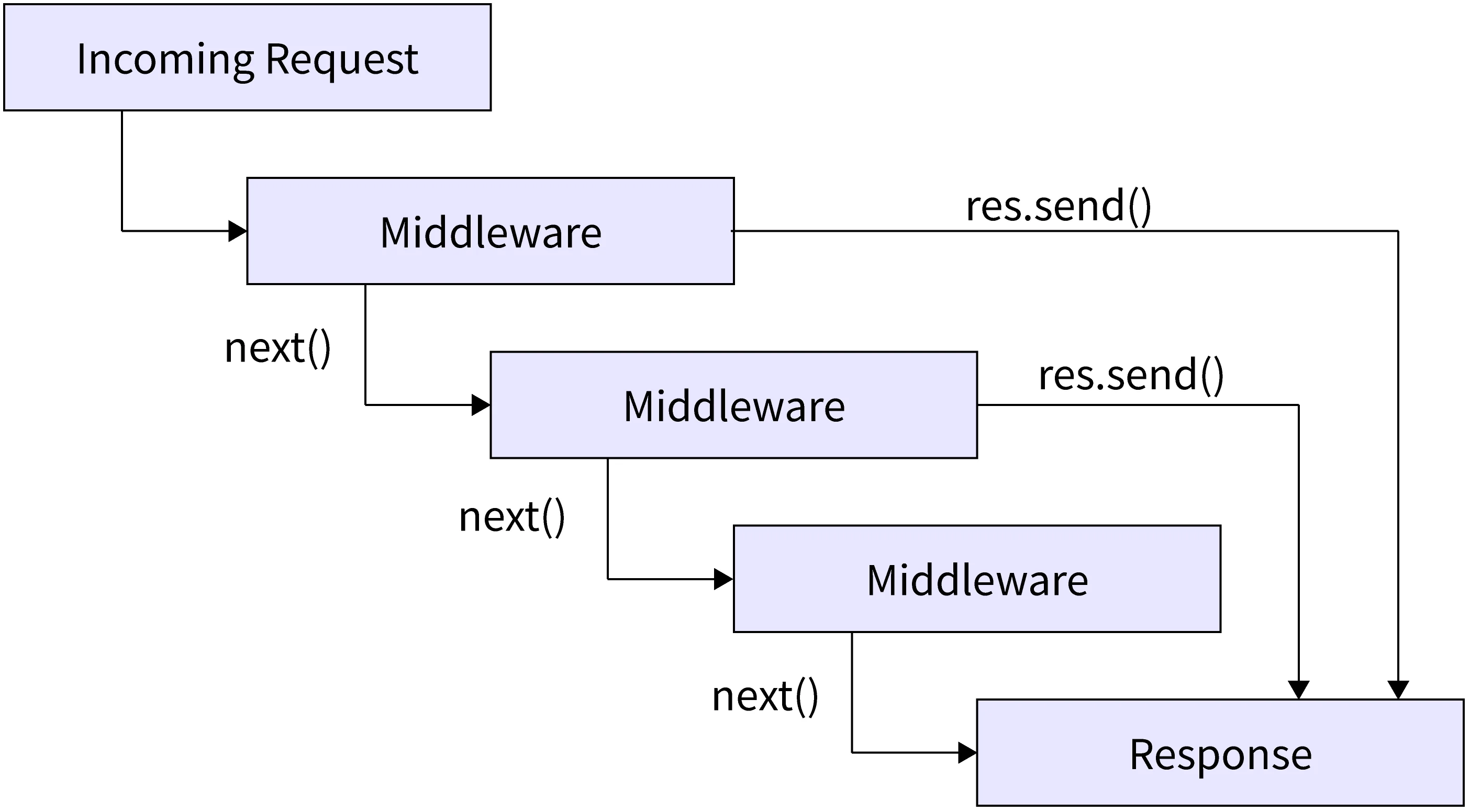
4)第三方中间件
2. 定义中间件
1)定义全局中间件
声明中间件函数
let recordMiddleware = function(request, response, next){
// 实现功能代码
// .....
// 执行next函数 (当如果希望执行完中间件函数之后,仍然继续执行路由中的回调函数,必须调用next)
next();
}应用中间件
// 没有挂载路径的中间件,应用的每个请求都会执行该中间件
app.use(recordMiddleware)声明时可以直接将匿名函数传递给 use。
app.use(function (request, response, next) {
console.log('定义第一个中间件');
next();
})多个全局中间件
express 允许使用 app.use() 定义多个全局中间件。
app.use(function (request, response, next) {
console.log('定义第一个中间件');
next();
})
app.use(function (request, response, next) {
console.log('定义第二个中间件');
next();
})2)定义路由中间件
如果只需要对某一些路由进行功能封装,则就需要路由中间件。
app.get('/路径', `中间件函数`, (request, response) => {
});
app.get('/路径', `中间件函数1`, `中间件函数2`, (request, response) => {
});3)静态资源中间件
express 内置处理静态资源的中间件。
// 引入 express 框架
const express = require('express');
// 创建服务对象
const app = express();
// 静态资源中间件的设置,将当前文件夹下的 public 目录作为网站的根目录
app.use(express.static('./public')); // 当然这个目录中都是一些静态资源
// 如果 public 目录下有 index.html 文件,单独也有 index.html 的路由
// 则谁书写在前,优先执行谁
app.get('/index.html', (request, response) => {
respsonse.send('首页');
});
// 监听端口
app.listen(3000, () => {
console.log('3000 端口启动....');
});注意事项:
如果静态资源与路由规则同时匹配,谁先匹配谁就响应。
路由响应动态资源,静态资源中间件响应静态资源。
4)错误处理中间件
为什么需要错误处理中间件?因为如果没有错误处理中间件,如果服务器代码执行出错,会把错误详细信息抛到用户页面上,这个是很危险的。
错误处理中间件和其他中间件定义类似,只是要使用 4 个参数,而不是 3 个,其写法如下: (err, req, res, next)。
app.use(function(err, req, res, next) {
console.error(err.stack);
res.status(500).send('Something broke!');
});注意:
- 错误处理中间件有 4 个参数,定义错误处理中间件时必须使用这 4 个参数。即使不需要 next 对象,也必须在签名中声明它,否则中间件会被识别为一个常规中间件,不能处理。
- 错误处理中间件需要挂载在所有路由和中间件的后面,如果路由回调函数或前面的中间件中出现错误,会自动进入错误处理中间件!
六、Router
1. 什么是 Router
可使用 express.Router 类创建模块化、可挂载的路由系统。Router 实例是一个完整的中间件和路由系统,因此常称其为一个 mini-app。
2)Router 作用
对路由进行模块化,更好的管理路由。
3)Router 使用
创建独立的 JS 文件(homeRouter.js)
// 1. 导入 express
const express = require('express');
// 2. 创建路由器对象
const router = express.Router();
// 3. 在 router 对象身上添加路由
router.get('/', (req, res) => {
res.send('首页');
})
router.get('/cart', (req, res) => {
res.send('购物车');
});
// 4. 暴露
module.exports = router;主文件
const express = require('express');
const app = express();
// 5.引入子路由文件
const homeRouter = require('./routes/homeRouter');
// 6.设置和使用中间件
app.use(homeRouter);
// app.use('/home', userRoutes);
app.listen(3000,()=>{
console.log('3000 端口启动....');
})七、模板引擎
1. 常见的模板引擎
- Ejs 模板引擎 ✔
- Jade 模板引擎
- swig 模板引擎
- handlerbar 模板引擎
2. 使用
1)安装并导入
npm install ejs
const ejs = require('ejs')2)模板引擎设置
// 1.设置 express 所使用的模板引擎, 会根据这里的设置自动引入模板引擎, 无需再写 require()
app.set('view engine', 'ejs');
// 2.设置模板文件的存放目录
app.set('views', path.join(__dirname, 'pages')); // 等于 __dirname + ./pages可以修改 ejs 模板引擎名字。修改后,模板文件后缀需要从 .ejs 改为 .html。
// 1.更改模板引擎名字为 html
app.engine('html', ejs.renderFile);
// 2.设置 express 所使用的模板引擎
app.set('view engine', 'html');3)渲染
app.get('/', function (req, res) {
// 会在模板文件的存放目录中查找 index.ejs 文件
res.render('index', { title: 'Hey', message: 'Hello there!'});
});其他渲染方法:
// -------------------- 渲染出 HTML --------------------
/*
第一种用法
渲染字符串
str: 模板文件名 data: 动态数据, js 对象
*/
ejs.render(str, data, options); // => 输出绘制后的 HTML 字符串
/*
第二种用法
渲染文件
str: 模板文件名 data: 动态数据, js 对象
*/
ejs.renderFile(filename, data, options, function(err, str){
// str => 输出绘制后的 HTML 字符串
});
/*
第三种用法
str: 模板文件名 data: 动态数据, js 对象
*/
const template = ejs.compile(str, options);
template(data); // => 输出绘制后的 HTML 字符串4)修改模板文件扩展名
修改为 .ejs。
5)修改模板内容
(1) 执行语句:其实就是写 js 代码的地方。
<% code %><% top.forEach(item => { %>
<tr>
<td><%= item.id %></td>
<td><%= item.name %></td>
<td><%= item.money %> 亿美元</td>
</tr>
<% }) %>(2) 输出转义的数据到模板上
<%= code %><p class="alert alert-warning">
<%= Date.now() %> <br>
<%= Math.random() %> <br>
<%= 10 * 7 + 8 %> <br>
</p>(3) 输出非转义的数据到模板上
<%- code %><%# 如果 code 的值中有html标签, 会被转义成字符实体, 原样显示 %>
<%= code %>
<%# 如果 code 的值中有html标签, 浏览器会解析处理 (标签字符串解析为DOM) %>
<%- code %>第七章:会话控制
一、cookie
express 中可以使用 cookie-parser 进行处理。
首先,需要使用 npm 安装 cookie-parser。在命令行中输入以下命令:
npm install cookie-parser然后,在 Express 应用中引入并使用 cookie-parser:
var express = require('express');
var cookieParser = require('cookie-parser');
var app = express();
app.use(cookieParser());现在,可以在路由处理函数中访问 req.cookies 来获取请求中的 cookies。例如:
app.get('/', function(req, res) {
console.log('Cookies: ', req.cookies);
});如果想设置一个 cookie,可以使用 res.cookie() 函数。例如:
app.get('/', function(req, res) {
res.cookie('name', 'express').send('cookie set'); // 设置 'name' cookie
});要删除 cookie,可以使用 res.clearCookie() 函数。例如:
app.get('/clear_cookie', function(req, res){
res.clearCookie('name');
res.send('cookie name cleared');
});给 cookie 添加时效
在使用 res.cookie() 方法设置 cookie 时,可以传递一个选项对象作为第三个参数,其中一个选项是 maxAge,它设置了 cookie 的有效期。maxAge 的值是以毫秒为单位的。
例如,如果想要一个有效期为 1 天的 cookie,可以这样设置:
res.cookie('name', 'value', { maxAge: 24 * 60 * 60 * 1000 });另一个可用的选项是 expires,它接受一个 Date 对象,表示 cookie 的过期日期和时间。例如:
let date = new Date();
date.setDate(date.getDate() + 1); // 设置日期为当前日期的下一天
res.cookie('name', 'value', { expires: date });在这个例子中,expires 被设置为当前日期和时间的下一天,这样也就设置了一个 24 小时后过期的 cookie。
注意:maxAge 和 expires 只能选择一个来设置,如果两者都设置了,maxAge 会优先被使用。
二、session
express-session 是一个用于处理 session 的 Express 中间件。
首先,需要使用 npm(Node 包管理器)安装 express-session。在命令行中输入以下命令:
npm install express-session然后,在 Express 应用中引入并使用 express-session:
var express = require('express');
var session = require('express-session');
var app = express();
app.use(session({
name: 'sid', // 设置 cookie 的 name,默认值是:connect.sid
secret: 'your secret key', // 用于签名 session ID 的字符串,可以是一个秘密字符串
resave: true, // 强制将 session 保存回 session 存储区,即使在请求期间 session 没有被修改
saveUninitialized: false, // 强制将未初始化的 session 存储。当新的 session 被创建但未被修改时,它就处于未初始化状态。
store: MongoStore.create({
mongoUrl: 'mongodb://127.0.0.1:27017/project' // 数据库的连接配置
}),
cookie: {
secure: true, // secure 设置为 true,表示只有 https 协议才能传递 cookie
httpOnly: true, // 开启后前端无法通过 JS 操作
maxAge: 1000 * 300 // 这一条 是控制 sessionID 的过期时间的!!!
}
}));现在,你可以在你的路由处理函数中访问 req.session 来获取和设置 session 数据。例如:
app.get('/', function(req, res) {
if(req.session.views) {
req.session.views++;
res.send("You visited this page " + req.session.views + " times");
} else {
req.session.views = 1;
res.send("Welcome to this page for the first time!");
}
});在这个例子中,我们在 session 中设置了一个 views 属性,用于跟踪用户访问首页的次数。
注意,express-session 中间件的配置可以根据你的需要进行修改。例如,你可能需要改变 secret,或者根据你的应用是否使用 HTTPS 来改变 cookie.secure 的值。此外,你可能还需要配置 session 存储,以便在多个服务器实例之间共享 session,或者在服务器重启后保持 session。
要销毁会话,可以使用 req.session.destroy() 方法:
app.get('/logout', (req, res) => {
req.session.destroy((err) => {
if(err) {
return console.log(err);
}
res.redirect('/');
});
});三、token
jsonwebtoken 是一个非常流行的 Node.js 包,用于生成和验证 JSON Web Tokens (JWT)。
首先,需要安装 jsonwebtoken 包,可以使用 npm 或者 yarn 来安装:
npm install jsonwebtoken
# 或者
yarn add jsonwebtoken然后,可以使用 jsonwebtoken 来生成一个 token:
const jwt = require('jsonwebtoken');
const data = {
id: 1,
name: 'John Doe'
};
const secret = 'your-own-secret-key';
const token = jwt.sign(data, secret, { expiresIn: '1h' });
console.log(token);创建了一个包含用户信息(id 和 name)的 token。sign 函数的第二个参数是一个 secret key,用于生成 token。第三个参数是一个选项对象,其中 expiresIn 属性定义了 token 的有效期。
然后,可以使用 jsonwebtoken 来验证一个 token:
const jwt = require('jsonwebtoken');
const token = 'the-token-you-want-to-verify';
const secret = 'your-own-secret-key';
try {
const decoded = jwt.verify(token, secret);
console.log(decoded);
} catch (err) {
console.error('Token verification failed:', err);
}使用 verify 函数来验证一个 token。如果 token 有效,verify 函数会返回解码后的数据。如果 token 无效(例如,如果它已过期或者如果它没有使用正确的 secret key 生成),verify 函数会抛出一个错误。
是的,jwt.verify() 函数也可以接受一个回调函数作为其第三个参数。这个回调函数会在验证过程完成后被调用。如果验证成功,回调函数的第一个参数(通常我们称之为 err)将为 null,第二个参数将包含解码后的 JWT。如果验证失败,err 将包含错误信息。
以下是一个使用回调函数的例子:
const jwt = require('jsonwebtoken');
const token = 'the-token-you-want-to-verify';
const secret = 'your-own-secret-key';
jwt.verify(token, secret, (err, decoded) => {
if (err) {
console.error('Token verification failed:', err);
} else {
console.log(decoded);
}
});在这个例子中,如果 token 验证失败,我们将打印错误信息。如果验证成功,我们将打印解码后的 JWT 数据。
请注意,使用回调函数使得 jwt.verify() 变为异步操作,这意味着你不能立即获取到验证结果,而需要在回调函数中处理结果。
拓展
一、Express 项目生成器 express-generator
全局安装:
npm install -g express-generator运行命令生成目录结构并指定模板引擎为 ejs:
express --view=ejs安装依赖:
npm install启动项目:
npm start注意:不要直接运行入口文件!
二、EventLoop
在 Node.js 中,事件驱动和事件循环是紧密相关的两个概念。它们一起构成了 Node.js 的异步非阻塞 I/O 模型的核心。
事件驱动是指 Node.js 的执行模型。在 Node.js 中,当一个操作(如网络请求、文件 I/O)开始时,它将注册一个回调函数并立即返回,这样 Node.js 就可以继续执行其他代码,而不需要等待这个操作完成。当这个操作完成时(或发生错误时),它将触发一个事件,并调用之前注册的回调函数。这就是事件驱动模型:代码的执行是由事件的发生驱动的。
事件循环是实现事件驱动模型的机制。在 Node.js 中,事件循环是一个无限循环,它持续地检查是否有事件发生,并调用相应的回调函数。事件循环有多个阶段,每个阶段负责处理不同类型的事件。例如,有一个阶段处理 I/O 事件,另一个阶段处理定时器事件,还有一个阶段处理微任务(如 Promise.then 和 process.nextTick)。
事件驱动和事件循环共同决定了 Node.js 的行为:Node.js 通过事件循环来检查和处理事件,而这些事件是由各种操作(如网络请求、文件 I/O)的完成或错误触发的,这就是事件驱动模型。这种模型使得 Node.js 能够在处理大量并发操作时保持高效率,因为它不需要在一个操作完成前阻塞其他操作。
1. 事件循环机制做的是什么事情?
事件循环机制用于管理异步 API 的回调函数什么时候回到主线程中执行。
Node.js 采用的是异步 IO 模型。同步 API 在主线程中执行,异步 API 在底层的 C++ 维护的线程中执行,异步 API 的回调函数也会在主线程中执行。
在 Javascript 应用运行时,众多异步 API 的回调函数什么时候能回到主线程中调用呢?这就是事件环环机制做的事情,管理异步 API 的回调函数什么时候回到主线程中执行。
2. 六个阶段
在 Node 中的事件循环分为六个阶段。
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘ ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ ┌─────────────┴─────────────┐ └───────────────┘
│ │ check │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘定时器检测阶段 (timers):这个阶段执行 timer (setTimeout、setInterval) 的回调。
待定回调 (Pending callbacks):执行与操作系统相关的回调函数,比如启动服务器端应用时监听端口操作的回调函数、TCP 错误、那些被推迟到下一个循环迭代的 I/O 回调函数。
闲置阶段 (idle, prepare):只供 libuv 内部使用。
轮询阶段 (poll):检索新的 I/O 事件;执行与 I/O 相关的回调(几乎所有情况下,除了关闭的回调函数,那些由计时器和 setImmediate() 调度的之外),其余情况 node 将在适当的时候在此阻塞。
在这个阶段需要特别注意,如果事件队列中有回调函数,则执行它们直到清空队列 ,否则事件循环将在此阶段停留一段时间以等待新的回调函数进入。
但是对于这个等待并不是一定的,而是取决于以下两个条件:
- 如果 setlmmediate 队列(check 阶段)中存在要执行的调函数。这种情况就不会等待。
- timers 队列中存在要执行的回调函数,在这种情况下也不会等待。事件循环将移至 check 阶段,然后移至 Closing callbacks 阶段,并最终从 timers 阶段进入下一次循环。
检查阶段 (check):setImmediate() 回调函数在这里执行。
关闭事件回调阶段 (close callback):一些关闭的回调函数,如:socket.on('close', ...) 。
3. 宏任务与微任务
跟浏览器中的 js 一样,node 中的异步代码也分为宏任务和微任务,只是它们之间的执行顺序有所区别。
我们再来看看 Node 中都有哪些宏任务和微任务。
宏任务 (MacroTasks)
- setlnterval
- setimeout
- setlmmediate(Node.js 环境)
- I/O
微任务 (MicroTasks)
- Promise 的回调。比如:Promise.then、Promise.catch、Promise.finally。
- process.nextTick(Node.js 环境)
事件循环的一个周期称为一个 "tick"
术语 "tick" 通常被用来描述事件循环的一个完整周期。每个 "tick" 包括以下步骤:
- 选择并执行一个宏任务:事件循环从宏任务队列(有时称为任务队列)中取出一个宏任务(如果有的话)并执行它。这包括诸如 setTimeout、setInterval 和 I/O 事件的回调函数。
- 执行微任务队列:在当前宏任务执行完毕后,事件循环会立即处理所有微任务队列中的任务。这包括 Promise 回调和 MutationObserver 回调。只要微任务队列不为空,就会连续执行微任务,直到清空队列。
- 更新渲染(仅限浏览器):在浏览器环境中,如果有必要,渲染步骤(如重绘和布局)可能会在这里发生。
- 检查是否有其他宏任务:如果有更多宏任务等待执行,事件循环将从步骤 1 开始重复上述过程。
每个 "tick" 可以看作是事件循环的一个迭代,它处理了一个宏任务和它产生的所有微任务。在每个 "tick" 的结束,如果在浏览器中,可能会有一次渲染操作,然后事件循环可能会进入下一个 "tick",选择下一个宏任务开始执行。这个过程持续不断地进行,直到没有更多的宏任务需要处理。
对于微任务还有个点需要特别注意。在 Node.js 中,process.nextTick 是一个特殊的调度操作,它不是事件循环的一部分,而是一个独立的机制。当你使用 process.nextTick 函数时,你提供的回调函数会被添加到一个特别的队列中。这个队列的回调将在当前操作完成后、事件循环继续之前执行,这意味着它会在任何 I/O 事件(包括定时器)或渲染操作之前执行。
这里的 "下一次 tick" 实际上不是指事件循环的下一个循环,而是指当前执行栈清空后立即执行的 "tick"。这允许开发者确保在继续其他事件循环操作之前,代码会尽快地执行。
这里是 process.nextTick 的工作流程:
- 当前执行栈中的代码执行完毕。
- process.nextTick 队列中的所有回调函数被执行。如果在执行这些回调的过程中又有新的 process.nextTick 被添加,那么这些新的回调也会在当前的 "tick" 中执行,这个队列会清空直到没有更多的 nextTick 回调为止。
- 微任务队列(包括 Promise 回调和 queueMicrotask)将在 process.nextTick 队列清空后执行。
- 接下来事件循环会继续到下一个阶段(例如定时器或 I/O 事件)。
因此,process.nextTick 不仅仅是在事件循环的下一个 "tick" 中执行代码,而是在当前 JavaScript 执行栈清空之后、事件循环继续之前执行代码。这种机制使得 process.nextTick 非常适合处理需要立即执行的操作,但又不想阻塞后续 I/O 操作的情况。
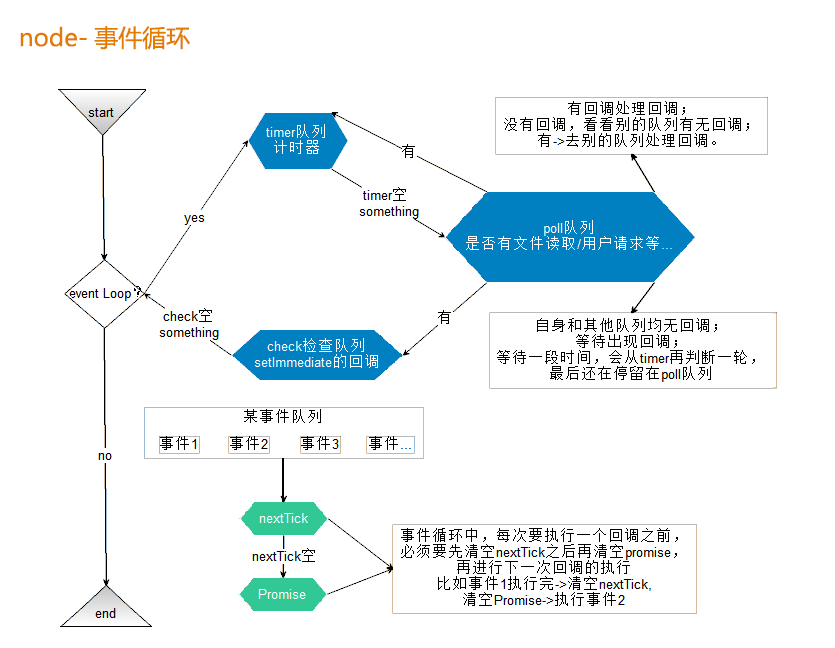
下面用代码实操来验证前面所说的。
题目一
console.log("start");
setTimeout(() => {
console.log("setTimeout 1");
});
setTimeout(() => {
console.log("setTimeout 2");
});
console.log("end");输出结果:
start
end
setTimeout 1
setTimeout 2结论:先执行同步再执行异步。
**题目二:**setTimeout 一定会先于 setImmediate 执行吗?
console.log("start");
setTimeout(() => {
console.log("setTimeout");
});
setImmediate(() => {
console.log("setImmediate");
});
const sleep = (delay) => {
const startTime = +new Date();
while (+new Date() - startTime < delay) {
continue;
}
};
sleep(2000);
console.log("end");输出结果:
start
end
setTimeout
setImmediate接下来我们来改造下上面的代码,把延迟器去掉,看看会输出什么。
setTimeout(() => {
console.log("setTimeout");
});
setImmediate(() => {
console.log("setImmediate");
});输出结果:结果不确定。
怎么回事呢?不是先 timers 阶段再到 check 阶段吗?怎么会变呢?
其实这就得看进入事件循环的时候,异步回调有没有完全准备好了。对于最开始的例子,因为有 2000 毫秒的延迟,所以进入事件循环的时候,setTimeout 回调是一定准备好了的。所以执行顺序不会变。但是对于这个例子,因为主线程没有同步代码需要执行,所以一开始就进入事件循环,但是在进入事件循环的时候,setTimeout 的回调并不是一定完全准备好的,所以就会有先到 check 阶段执行 setImmediate 回调函数,再到下一次事件循环的 timers 阶段来执行 setTimeout 的回调。
那在什么情况下同样的延迟时间,setImmediate 回调函数一定会优先于 setTimeout 的回调呢?
其实很简单,只要将这两者放到 timers 阶段和 check 阶段之间的 Pending callbacks、idle,prepare、poll 阶段中任意一个阶段就可以了。因为这些阶段完执行完是一定会先到 check 再到 timers 阶段的。以 poll 阶段为例,将这两者写在 IO 操作中。
const fs = require("fs");
fs.readFile("./fstest.js", "utf8", (err, data) => {
setTimeout(() => {
console.log("setTimeout");
});
setImmediate(() => {
console.log("setImmediate");
});
});输出结果:
setImmediate
setTimeout题目三
主线程同步代码执行完毕后,会先执行微任务再执行宏任务。
console.log("start");
setTimeout(() => {
console.log("setTimeout");
});
setImmediate(() => {
console.log("setImmediate");
});
Promise.resolve().then(() => {
console.log("Promise.resolve");
});
console.log("end");输出结果:
start
end
Promise.resolve
setTimeout
setImmediate结论:先微任务再宏任务。
题目四
console.log("start");
setTimeout(() => {
console.log("setTimeout");
});
setImmediate(() => {
console.log("setImmediate");
});
Promise.resolve().then(() => {
console.log("Promise.resolve");
});
process.nextTick(() => {
console.log("process.nextTick");
});
console.log("end");输出结果:
start
end
process.nextTick
Promise.resolve
setTimeout
setImmediate结论:nextTick 优于其它微任务。
题目五
// timers 阶段
setTimeout(() => {
console.log("setTimeout");
Promise.resolve().then(() => {
console.log("setTimeout Promise.resolve");
});
});
// check 阶段
setImmediate(() => {
console.log("setImmediate");
Promise.resolve().then(() => {
console.log("setImmediate Promise.resolve");
});
});
// 微任务
Promise.resolve().then(() => {
console.log("Promise.resolve");
});
// 微任务
process.nextTick(() => {
console.log("process.nextTick");
Promise.resolve().then(() => {
console.log("nextTick Promise.resolve");
});
});输出结果:
process.nextTick
Promise.resolve
nextTick Promise.resolve
setTimeout
setTimeout Promise.resolve
setImmediate
setImmediate Promise.resolve结论:微任务穿插在各个阶段间执行。
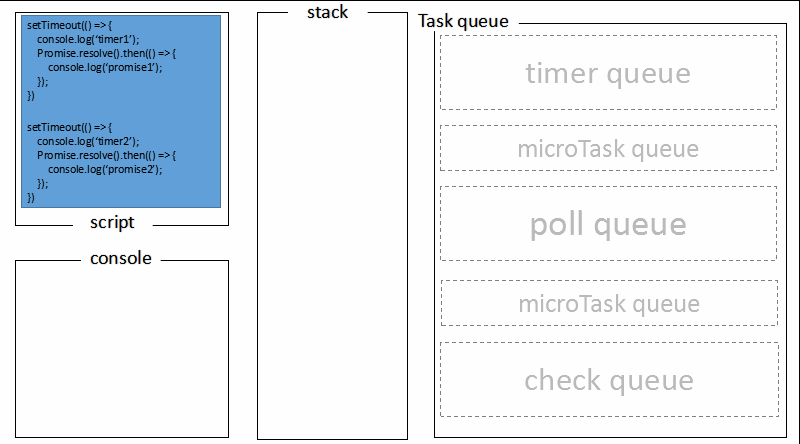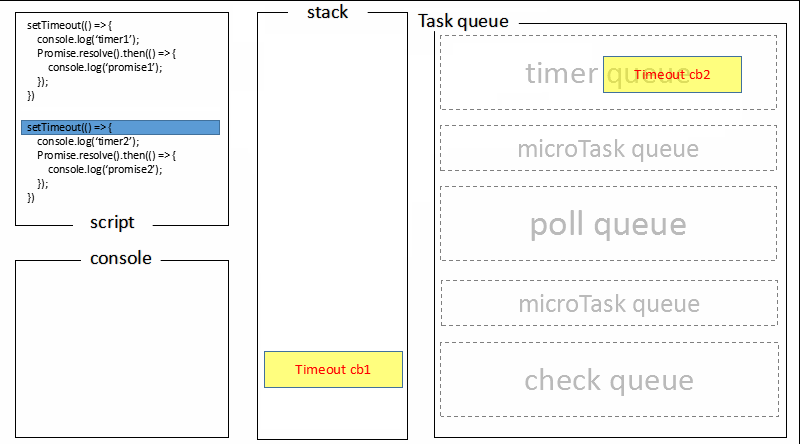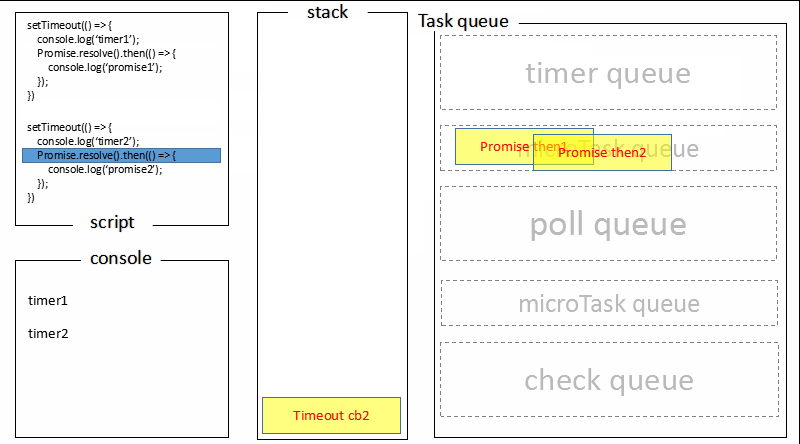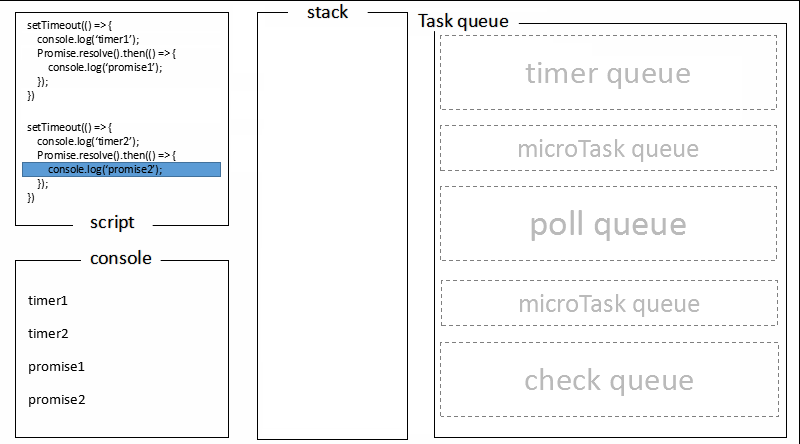
题目六