
正则表达式

第一章:邂逅正则
一、什么是正则表达式?
正则表达式(Regular Expression),在计算机科学中,是一种用于描述字符序列规则的语法。它主要用于字符串的匹配、查找、替换和分割。正则表达式是一种强大的文本处理工具,被广泛应用于各种编程语言和文本处理工具中。
正则表达式由一系列字符和特殊符号组成,这些字符和符号按照一定的规则组合在一起,形成了一种模式,这种模式可以用来描述一类字符串。例如,正则表达式 a.b 可以匹配"axb"、"ayb"等字符串,其中 . 是一个特殊符号,表示任意字符。
总结:一种描述文本内容组成规律的表示方式。更简单点就是规则表达式。
正则表达式:regular expression = RegExp
二、用途?
正则表达式是一种强大的文本处理工具,主要用于字符串的匹配、查找、替换和分割。以下是正则表达式的一些主要用途:
1)数据验证:正则表达式常用于验证用户输入的数据是否符合预期的格式,例如检查一个字符串是否是有效的电子邮件地址、电话号码、URL、日期格式等。
2)文本搜索:正则表达式可以用来在文本中搜索符合特定模式的字符串。例如,你可以使用正则表达式在一篇文章中查找所有的电子邮件地址或 URL。
3)文本替换:正则表达式可以用来替换文本中符合特定模式的部分。例如,你可以使用正则表达式将文本中的所有"colour"替换为"color"。
4)文本分割:正则表达式可以用来按照特定模式分割文本。例如,你可以使用正则表达式将一段文本按照逗号、空格或其他分隔符分割成多个部分。
5)语法高亮:许多文本编辑器和 IDE 使用正则表达式来实现语法高亮,通过识别语言的关键字、注释、字符串等元素,提高代码的可读性。
6)网络爬虫:在网络爬虫中,正则表达式常用于解析和提取网页中的信息。
7)日志分析:在日志分析中,正则表达式可以用来提取日志中的关键信息,帮助我们更好地理解和分析系统的运行情况。
正则表达式的应用非常广泛,几乎所有的编程语言都支持正则表达式,掌握正则表达式可以极大提高我们处理文本数据的效率。
三、正则表达式简史
简史
正则表达式的历史可以追溯到 20 世纪 50 年代,当时美国数学家斯蒂芬·科尔·克林(Stephen Cole Kleene)在研究自动机理论时,提出了正则表达式的概念。他发现可以使用一种简单的字符串表示法来描述自动机的状态转移。
然后在 20 世纪 70 年代,肯·汤普森(Ken Thompson)在开发 Unix 操作系统时,将正则表达式引入到了 ed 文本编辑器中,这是正则表达式首次被用于计算机软件中。随后,正则表达式被广泛应用于 Unix 系统的各种工具中,如 grep、awk 和 sed 等。
在 20 世纪 80 年代和 90 年代,正则表达式开始被引入到编程语言中。例如,Perl 语言提供了强大的正则表达式支持,这使得 Perl 成为了文本处理和报告生成等任务的首选语言。随后,许多其他的编程语言,如 Python、Java 和 JavaScript 等,也都引入了正则表达式支持。
到了 21 世纪,正则表达式已经成为了计算机科学和软件开发中的基础工具,被广泛应用于文本处理、数据验证、语法分析等各种场景中。
流派
1)POSIX 基础正则表达式(BRE):这是最早的正则表达式标准,定义了一些基本的元字符,如 *、.、^ 和 $ 等。BRE 在 Unix 工具(如 grep 和 sed)中被广泛使用。
2)POSIX 扩展正则表达式(ERE):这是对 BRE 的扩展,增加了一些新的元字符,如 +、? 和 | 等。ERE 在 Unix 工具(如 egrep)中被广泛使用。
3)Perl 兼容正则表达式(PCRE):这是 Perl 语言中使用的正则表达式标准,提供了许多强大的特性,如预查(lookahead)、后顾(lookbehind)、非贪婪匹配和反向引用等。PCRE 在许多现代编程语言(如 PHP、Python 和 JavaScript)中被广泛使用。
4).NET 正则表达式:这是 .NET 平台中使用的正则表达式标准,提供了一些独特的特性,如命名捕获组和右侧预查等。
5)Java 正则表达式:这是 Java 语言中使用的正则表达式标准,提供了一些独特的特性,如 Unicode 字符类和 POSIX 字符类等。
四、对正则的理解
正则表达式也是一门编程语言。
从编程语言发展史角度来理解
相较于通用编程语言 GPPL,正则表达式属于领域特定语言 DSL。
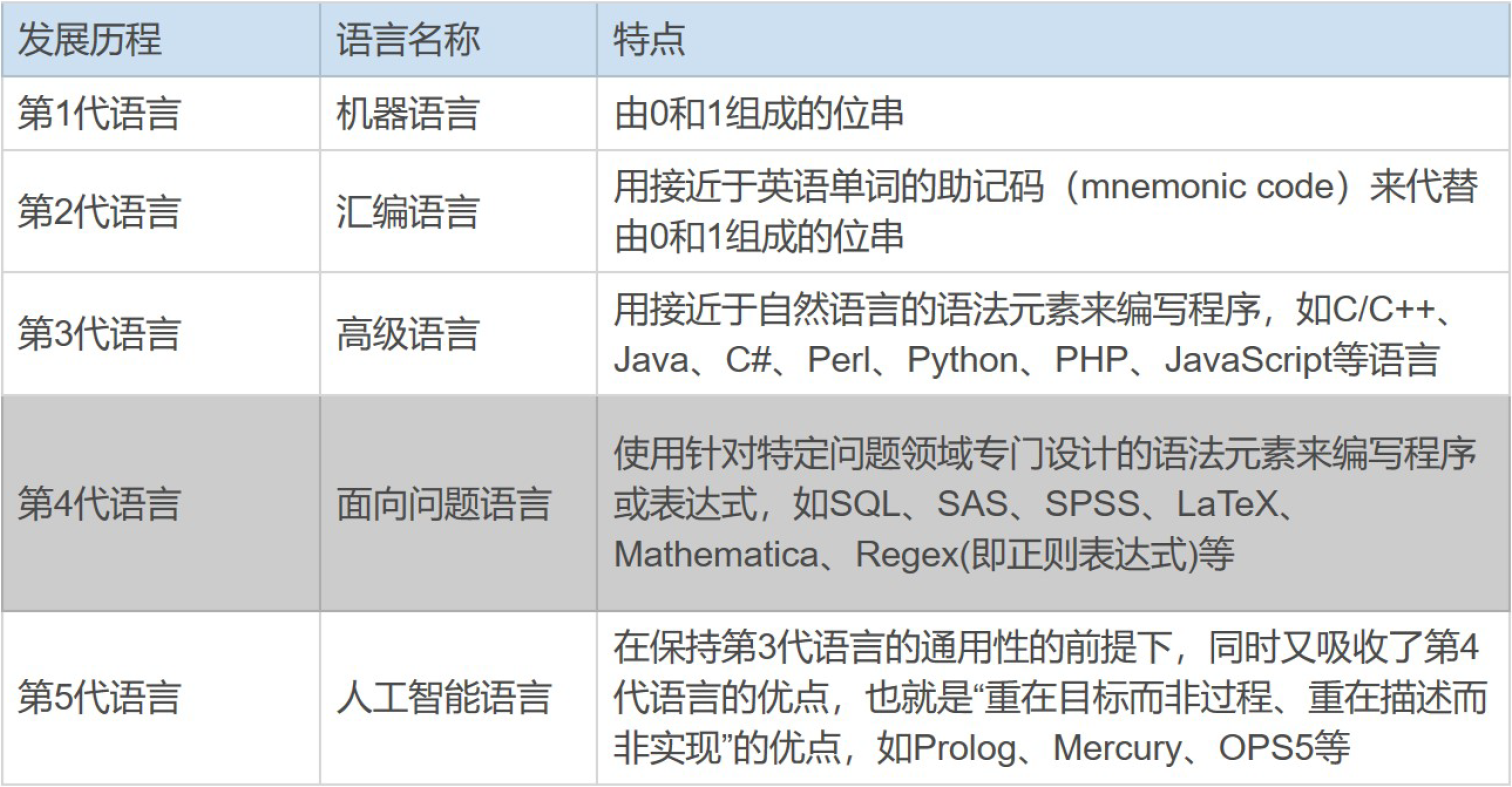
显然,正则表达式也是一种编程语言,而且是属于第 4 代语言——面向问题语言中的一种。
可以看到,第 4 代语言相对于第 3 代语言,更专注于某个特定、专门的业务逻辑和问题领域。程序员主要负责分析问题,以及使用第 4 代语言来描述问题,而无需花费大量时间,去考虑具体的处理逻辑和算法实现,处理逻辑和算法实现是由编译器(Compiler)或解释 器(Interpreter)这样的语言解析引擎来负责的。
事实上,最初之所以提出第 4 代语言的概念,其目的就是希望非专业程序员也能做应用开发,不过就目前情况来看,这个目的并没有得到很好的实现。
从编程范式角度来理解
正则表达式属于声明式编程。
正则表达式的语法元素本质上就是程序逻辑和算法
程序代码是对现实事物处理逻辑的抽象,而正则表达式,则是对复杂的字符匹配程序代码的进一步抽象;也就是说,高度简洁的正则表达式,可以认为其背后所对应的,是字符匹配程序代码,而字符匹配程序代码,背后对应的是字符匹配处理逻辑。
因此,我们可以这么认为,字符匹配处理逻辑,可以抽象为字符匹配程序代码;字符匹配程序代码,可以再进一步,抽象为高度简洁的正则表达式。

五、学习哪些内容
学习正则表达式时需要掌握的主要内容:
1)基础符号:了解正则表达式中的基础符号,如.(匹配任意单个字符)、*(匹配前面的子表达式零次或多次)、+(匹配前面的子表达式一次或多次)等。
2)字符类:如 [abc](匹配任何一个列在方括号中的字符)、\d(匹配数字)、\w(匹配字母或数字或下划线或汉字)等。
3)量词:如 *(零次或多次)、+(一次或多次)、?(零次或一次)、{n}(n次)、{n,}(至少n次)、{n,m}(至少 n 次,最多 m 次)等。
4)位置匹配:如 ^(匹配字符串的开始)、$(匹配字符串的结束)、\b(匹配一个单词的边界)等。
5)特殊字符:如 \t(匹配制表符)、\n(匹配换行符)等。
6)分组和引用:使用 () 进行分组,使用 \1、\2 等进行引用。
7)预查:正向预查和负向预查。
8)替换和分割:使用正则表达式进行字符串的替换和分割。
9)贪婪与懒惰:默认情况下,正则表达式是贪婪的,会尽可能多的匹配字符,可以使用 ? 使其变为懒惰模式,尽可能少的匹配字符。
10)正则表达式的应用:在各种编程语言中(如 JavaScript、Python、Java 等)如何使用正则表达式。
学习正则表达式需要大量的实践,可以通过在线的正则表达式测试工具(https://regex101.com)进行练习,以提高自己的技能。
第二章:了解正则
一、转义字符
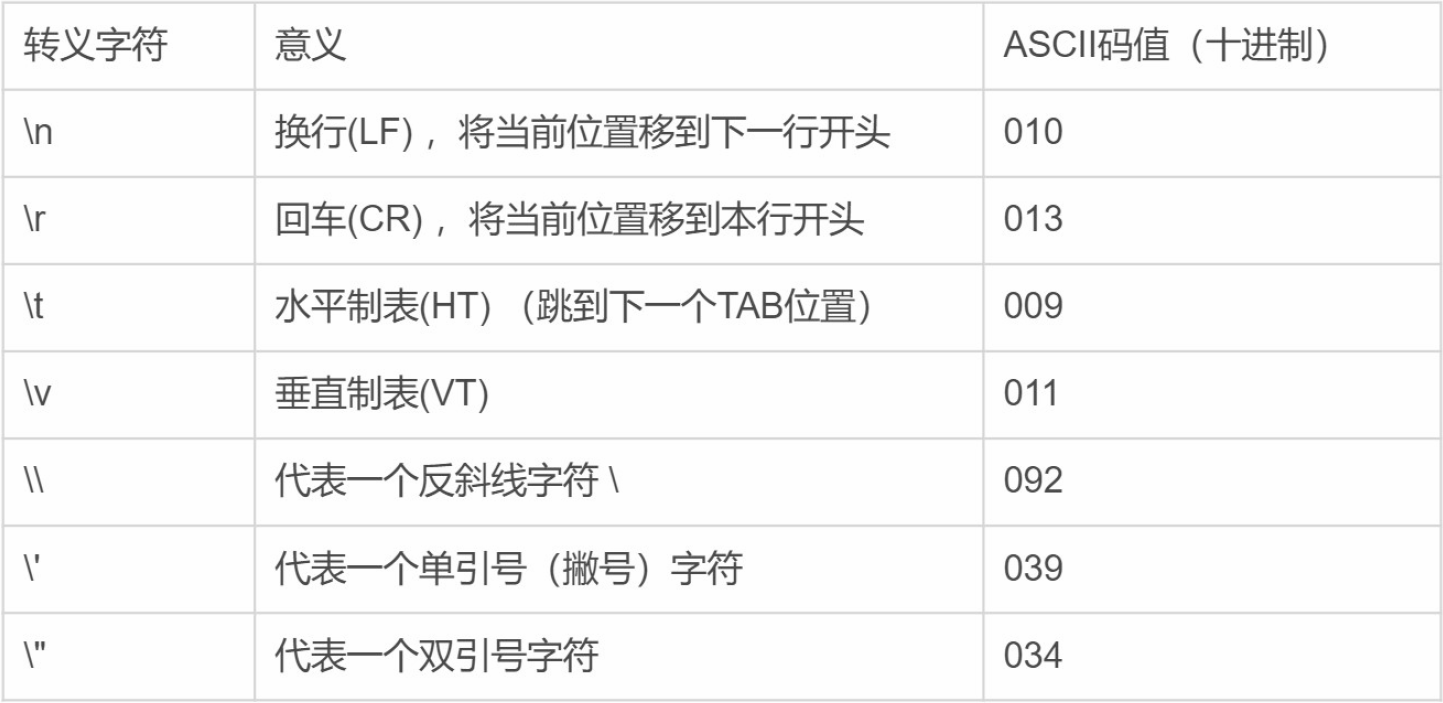
转义用于改变字符的含义,用来对某个字符有多种语义时的处理。
假如有这样的场景,如果我们想通过正则查找 / 符号,但是 / 在正则中有特殊的意义。如果写成 /// 这会造成解析错误,所以要使用转义语法 /\// 来匹配。
在大多数情况下,斜杠在正则表达式中只是一个普通字符,用于匹配斜杠字符本身。但在特定的编程语言或环境中,斜杠可能会被用作正则表达式的分隔符。例如,在 JavaScript 中,正则表达式的字面量形式使用斜杠作为分隔符,如
/pattern/。在这种情况下,斜杠用于标识正则表达式的开始和结束。
const url = "https://www.baidu.com";
console.log(/https:\/\//.test(url)); // true使用转义字符也可使元字符转换为普通字符。
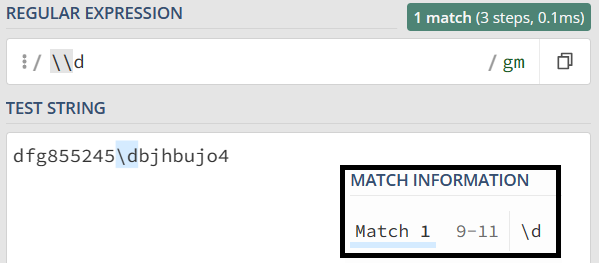
上面例子的反斜杠和 d 是连续出现的两个字符,如果你想表示成反斜杠或 d,可以用管道符号或中括号来实现,比如 \|d 或 [\d]。
使用 RegExp 构建正则时在转义上会有些区别,下面是对象与字面量定义正则时区别。
let price = 12.23;
// 含义1: . 除换行外任何字符 含义2: .普通点
// 含义1: d 字母d 含义2: \d 数字 0~9
console.log(/\d+\.\d+/.test(price));
// 字符串中 \d 与 d 是一样的,所以在 new RegExp 时,\d 即为 d
console.log("\d" == "d");
// 使用对象定义正则时,可以先把字符串打印一样,结果是字面量一样的定义就对了
console.log("\\d+\\.\\d+");
let reg = new RegExp("\\d+\\.\\d+");
console.log(reg.test(price));下面是网址检测中转义符使用。
let url = "https://www.baidu.com";
console.log(/https?:\/\/\w+\.\w+\.\w+/.test(url));结论:在使用字符串创建正则时,需要多加 \ ,可以通过打印输出到控制台看下正则正确嘛。需要用到转义符的字符 . * + ( ) $ / \ ? [ ] ^ { } 。
这是为什么呢?
在程序使用过程中,从输入的字符串到正则表达式,其实有两步转换过程,分别是字符串转义和正则转义。
在正则中正确表示“反斜杠”具体的过程是这样子:我们输入的字符串,四个反斜杠 \,经过第一步字符串转义,它代表的含义是两个反斜杠 \;这两个反斜杠再经过第二步正则转义,它就可以代表单个反斜杠 \了。

二、元字符的组成
1. 什么是元字符?
元字符就是指那些在正则表达式中具有特殊意义的专用字符。
2. 元字符有哪些?
1)特殊单字符 / 字符匹配符
| 元字符 | 解释 |
|---|---|
| . | 表示换行以外的任意单个字符。 |
| \d | 表示任意单个数字。 |
| \w | 表示任意单个数字或字母或下划线。\w 等价于 [a-zA-Z0-9_]。 |
| \s | 任意一个空白字符匹配,如空格,制表符 \t,换行符 \n 等。 |
| \D、\W 和 \S | 分别表示着和原来相反的意思。 |
小技巧:可以使用
[\s\S]或[\d\D]来匹配所有字符。
使用 . 匹配除换行符外任意字符,下面匹配不到 qq.com 因为有换行符。
const url = `
https://www.baidu.com
qq.com
`;
console.log(url.match(/.+/)[0]);使用 /s 视为单行模式(忽略换行)时,. 可以匹配所有。
let aaa = `
<span>
ddf
yxts
</span>
`;
let res = aaa.match(/<span>.*<\/span>/s);
console.log(res[0]);正则中空格会按普通字符对待。
let tel = `010 - 999999`;
console.log(/\d+-\d+/.test(tel)); // false
console.log(/\d+ - \d+/.test(tel)); // true2)范围 / 字符匹配符
| 元字符 | 解释 |
|---|---|
| | | 或 |
| - | 连字符 |
| [...] | 多选一,括号中任意单个元素。 |
| [0-9] | 匹配0到9的数字。 |
| [a-z] | 匹配小写 a 到 z 之间任意单个元素(按 ASCIl 表,包含 a、z)。 |
| [A-Z] | 匹配大写 a 到 z 之间任意单个元素(按 ASCIl 表,包含 A、Z)。 |
| [^...] | 取反,不能是括号中的任意单个元素。括号中第一个是脱字符(^) |
Java 的正则表达式默认区分大小写,如何实现不区分大小写?
(?i)abc表示 abc 都不区分大小写。a(?i)bc表示 bc 不区分大小写。a((?i)b)c表示只有 b 不区分大小写。也可以在 Pattern 的 compile 方法中加上参数 Pattern.CASE_INSENSIVE,如
Pattern pat = Pattern.compile(regEx, Pattern.CASE_INSENSIVE);。
也有把 | 元字符单独分类为选择匹配符(传统编程语言中的分支语句)。
3)空白符
| 元字符 | 解释 |
|---|---|
| \r | 回车符 |
| \n | 换行符 |
| \f | 换页符 |
| \t | 制表符 |
| \v | 垂直制表符 |
| \s | 任意空白符 |
4)量词 / 限定符
| 元字符 | 解释 |
|---|---|
| * | 0 到多次(无要求) 等价于 {0,} |
| + | 1 到多次(至少一次) 等价于 {1,} |
| ? | 0 到 1 次(最多一次) 等价于 {0,1} |
{m} | 出现 m 次 |
{m,} | 出现至少 m 次 |
{m,n} | m 到 n 次 |
语法不包括
{,m}这种形式。如果想要匹配至多 m 次,你可以使用{0,m}。可以把量词看成传统编程语言中的循环语句。
5)定位符
| 符号 | 含义 |
|---|---|
| ^ | 指定起始字符。 |
| $ | 指定结束字符。 |
| \b | 匹配目标字符串的边界。这里说的字符串的边界指的是子串间有空格,或者是目标字符串的结束位置。 |
| \B | 匹配目标字符串的非边界。和 \b 的含义刚刚相反。 |
6)断言
后面单独章节学习。
三、量词与贪婪
1. 引言
首先,观察下下面两个案例,并分析为什么会这样?
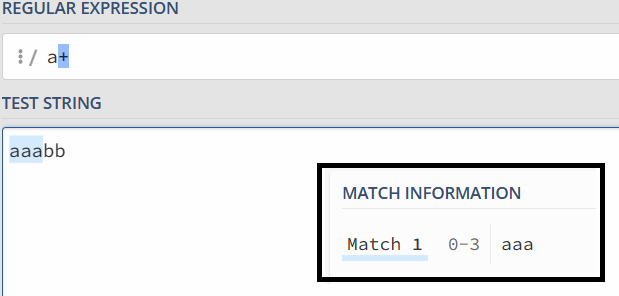
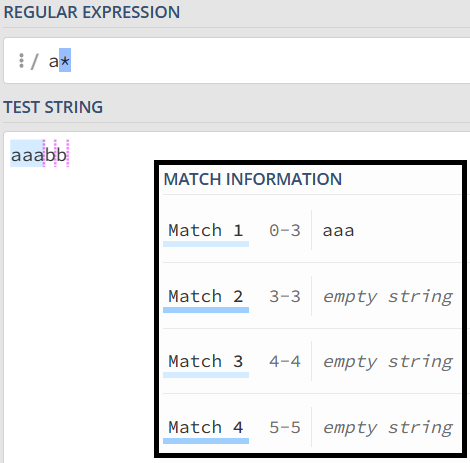
因为星号(*)代表 0 到多次,匹配 0 次就是空字符串。到这里,你可能会有疑问,如果这样,aaa 部分应该也有空字符串,为什么没匹配上呢?
这就引入了我们要讲的话题,贪婪与非贪婪模式。
2. 贪婪匹配(Greedy)
在正则中,表示次数的量词默认是贪婪的,在贪婪模式下,会尝试尽可能最大长度去匹配。
首先,我们来看一下在字符串 aaabb 中使用正则 a* 的匹配过程。
| 🔴🟡🟢 |
|---|
| 字符串 a a a b b 下标 0 1 2 3 4 |
| 匹配 | 开始 | 结束 | 说明 | 匹配内容 |
|---|---|---|---|---|
| 第 1 次 | 0 | 3 | 到第一个字母 b 发现不满足,输出 aaa | aaa |
| 第 2 次 | 3 | 3 | 匹配剩下的 bb,发现匹配不上,输出空字符串 | 空字符串 |
| 第 3 次 | 4 | 4 | 匹配剩下的 b,发现匹配不上,输出空字符串 | 空字符串 |
| 第 4 次 | 5 | 5 | 匹配剩下空字符串,输出空字符串 | 空字符串 |
贪婪模式的特点就是尽可能进行最大长度匹配。
3. 非贪婪匹配(Lazy)
在量词后面加上英文的问号 (?) ,正则就变成了 a*?。此时的匹配结果如下:
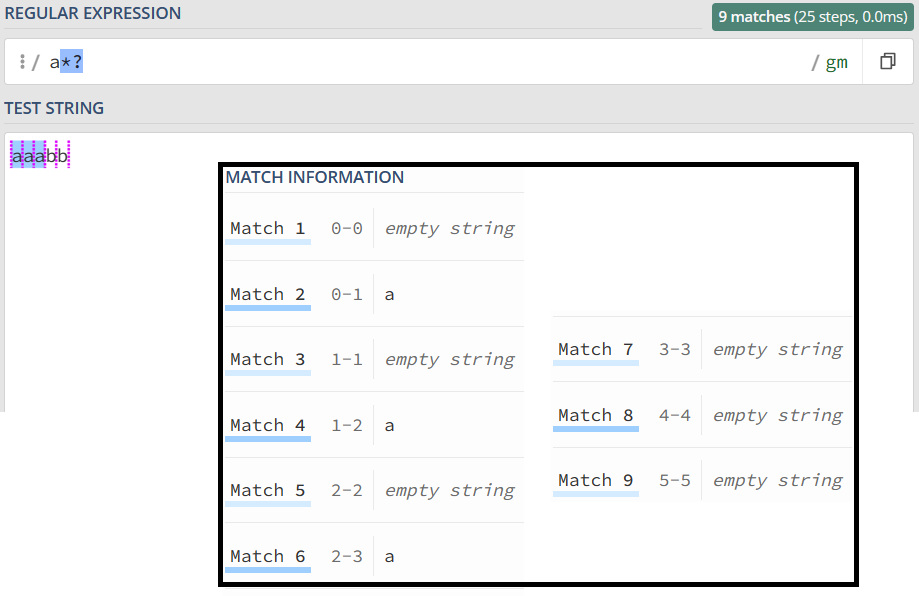
非贪婪模式的特点就是找出长度最小且满足要求的。
我们对比下贪婪模式与非贪婪模式。
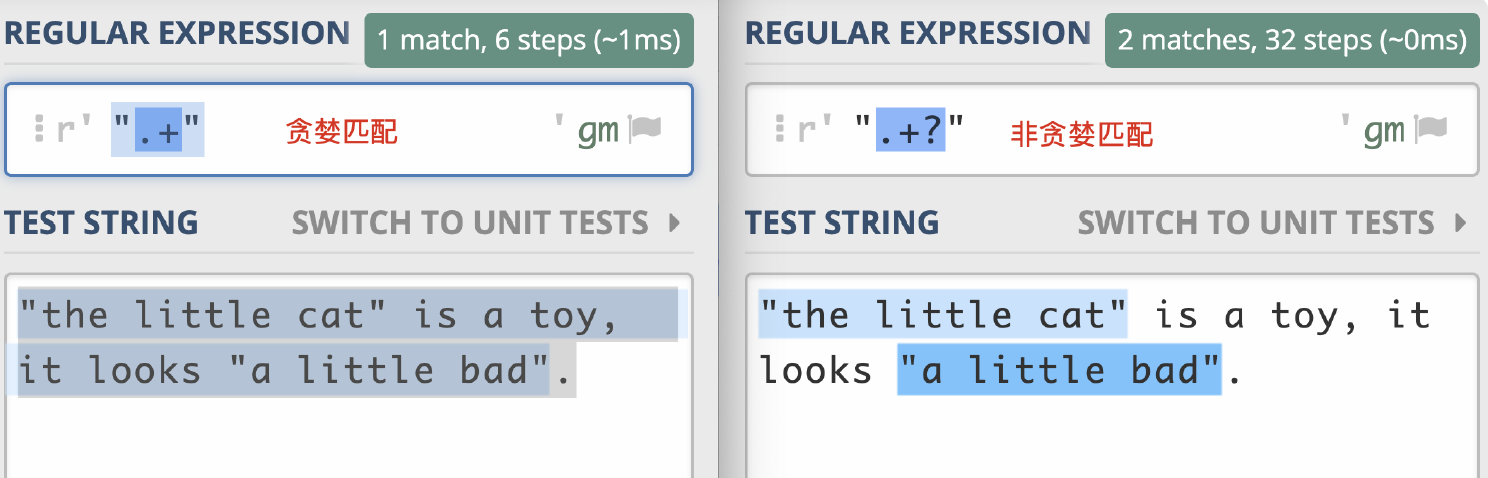
在实际开发中,使用非贪婪匹配更多。
4. 独占模式(Possessive)
不管是贪婪模式,还是非贪婪模式,都需要发生回溯才能完成相应的功能。但是在一些场景下,我们不需要回溯,匹配不上返回失败就好了,因此正则中还有另外一种模式是独占模式。
什么是回溯?
贪婪匹配(Greedy)
regex = "xy{1,3}z"
text = "xyyz"在匹配时,y{1,3} 会尽可能长地去匹配,当匹配完 xyy 后,由于 y 要尽可能匹配最长,即三个,但字符串中后面是个 z 就会导致匹配不上,这时候正则就会向前回溯,吐出当前字符 z,接着用正则中的 z 去匹配。

如果我们把这个正则改成非贪婪模式,如下:
regex = "xy{1,3}?z"
text = "xyyz"由于 y{1,3}? 代表匹配 1 到 3 个 y,尽可能少地匹配。匹配上一个 y 之后,也就是在匹配上 text 中的 xy 后,正则会使用 z 和 text 中的 xy 后面的 y 比较,发现正则 z 和 y 不匹配,这时正则就会向前回溯,重新查看 y 匹配两个的情况,匹配上正则中的 xyy,然后再用 z 去匹配 text 中的 z,匹配成功。

了解了回溯,我们再看下独占模式。
独占模式和贪婪模式很像,独占模式会尽可能多地去匹配,如果匹配失败就结束,不会进行回溯,这样的话就比较节省时间。具体的方法就是在量词后面加上加号(+)。
regex = "xy{1,3}+z"
text = "xyyz"
三种模式的对比
如果你用 a{1,3}+ab 去匹配 aaab 字符串,a{1,3}+ 会把前面三个 a 都用掉,并且不会回溯,这样字符串中内容只剩下 b 了,导致正则中加号后面的 a 匹配不到符合要求的内容,匹配失败。如果是贪婪模式 a{1,3} 或非贪婪模式 a{1,3}? 都可以匹配上。
| 模式 | 正则 | 文本 | 结果 |
|---|---|---|---|
| 贪婪模式 | a{1,3}ab | aaab | 匹配 |
| 非贪婪模式 | a{1,3}?ab | aaab | 匹配 |
| 独占模式 | a{1,3}+ab | aaab | 不匹配 |
练习
把下面的句子分割,要求有引号括起来的是整体。
we found "the little cat" is in the hat, we like "the little cat"答案:/[a-zA-Z]+|".*?"/gm
四、分组与引用
分组也叫原子组。
1. 引言
假设我们现在要去查找 15 位或 18 位数字。根据前面学习的知识,使用量词可以表示出现次数,使用管道符号可以表示多个选择,你应该很快就能写出 \d{15}|\d{18}。
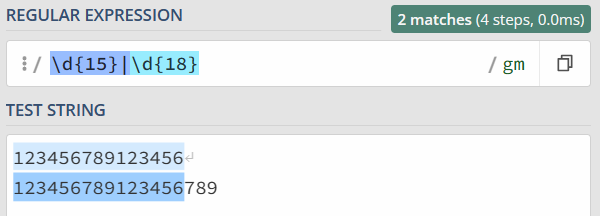
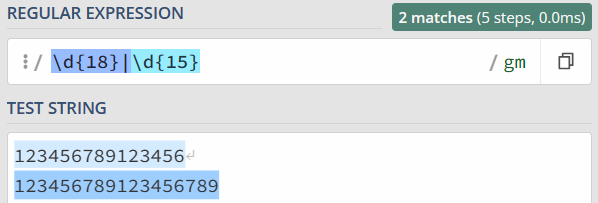
为了解决这个问题,你灵机一动,很快就想到了办法,就是把 15 和 18 调换顺序,即写成 \d{18}|\d{15}。你发现,这回符合要求了。
另外我们前面学习过,问号可以表示出现 0 次或 1 次,你发现可以使用“北京市?” 来实现来查找 “北京” 和 “北京市”。
同样,针对 15 或 18 位数字这个问题,可以看成是 15 位数字,后面 3 位数据有或者没有,你应该很快写出了 \d{15}\d{3}?。但这样写对不对呢?我们来看一下。
在上一节我们学习了量词后面加问号表示非贪婪,而我们现在想要的是 \d{3} 出现 0 次或 1次。
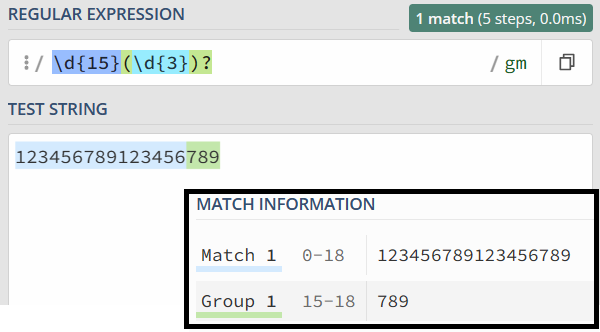
❎ 示例一:\d{15}\d{3}? 由于 \d{3} 表示三次,加问号表示非贪婪,还是 3 次。
✅ 示例二:\d{15}(\d{3})? 在 \d{3} 整体后加问号,表示后面三位有或无。
2. 分组与编号
括号在正则中可以用于分组,被括号括起来的部分“子表达式”会被保存成一个子组。
那分组和编号的规则是怎样的呢?其实很简单,用一句话来说就是,第几个括号就是第几个分组。

在括号嵌套的情况里,我们要看某个括号里面的内容是第几个分组怎么办?不要担心,其实方法很简单,我们只需要数左括号(开括号)是第几个,就可以确定是第几个子组。

日期分组编号是 1,时间分组编号是 5,年月日对应的分组编号分别是 2,3,4,时分秒的分组编号分别是 6,7,8。
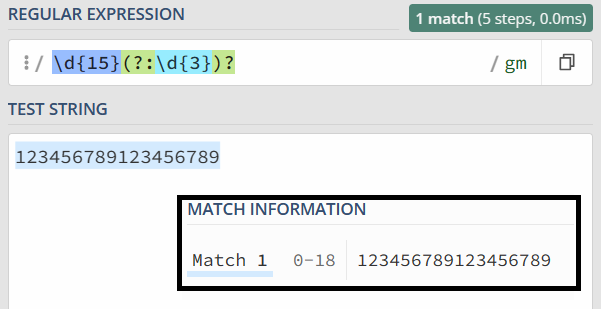
3. 不保存子组
在括号里面的会保存成子组,但有些情况下,你可能只想用括号将某些部分看成一个整体,后续不用再用它,类似这种情况,在实际使用时,是没必要保存子组的。这时我们可以在括号里面使用 ?: 不保存子组。
4. 命名分组
命名分组的格式为 (?P<分组名>正则) 或者 (?<分组名>正则)。
public static void main(String[] args) {
String content = "jieruigou NN GGG1237gou 9987gou";
String regStr = "(?<g1>\\d\\d)(?<g2>\\d\\d)";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
System.out.println("第 1 个分组内容:" + matcher.group(1));
System.out.println("第 1 个分组内容(通过组名):" + matcher.group("g1"));
System.out.println("第 2 个分组内容:" + matcher.group(2));
System.out.println("第 2 个分组内容(通过组名):" + matcher.group("g2"));
}
}命名分组 JavaScript 不支持,Java 支持。
5. 分组引用
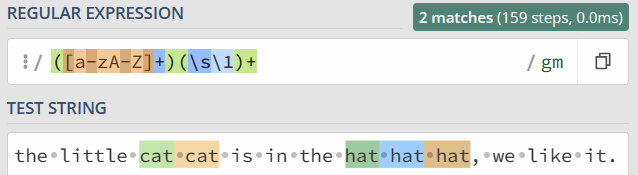
可以使用 “反斜扛 + 编号”,即 \number 的方式来进行引用。
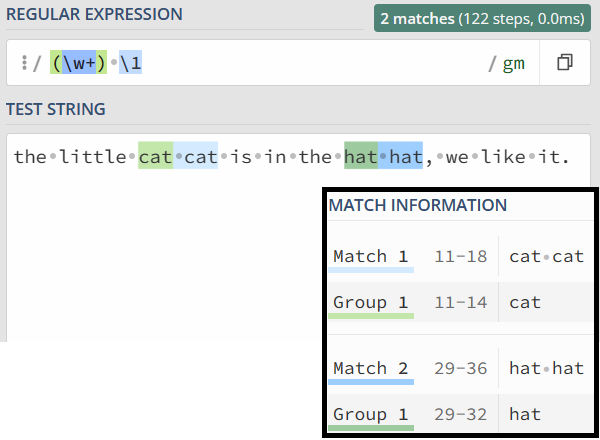
练习
有一篇英文文章,里面有一些单词连续出现了多次,我们认为连续出现多次的单词应该是一次,比如:
the little cat cat is in the hat hat hat, we like it.
其中 cat 和 hat 连接出现多次,要求处理后结果是:
the little cat is in the hat, we like it.
五、匹配模式 / 模式修饰
所谓匹配模式,指的是正则中一些改变元字符匹配行为的方式,比如匹配时不区分英文字母大小写。常见的匹配模式有 4 种,分别是不区分大小写模式、点号通配模式、多行模式和注释模式。
1. 常见的都有哪些?
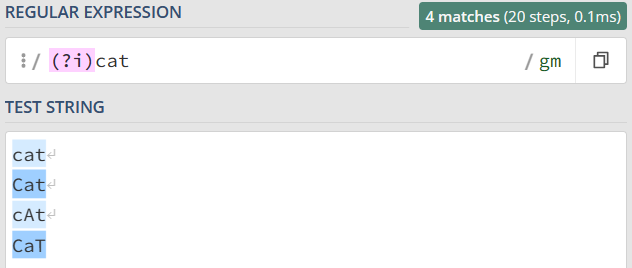
1)不区分大小写模式(Case-Insensitive)
模式修饰符是通过 (? 模式标识) 的方式来表示的。 我们只需要把模式修饰符放在对应的正则前,就可以使用指定的模式了。在不区分大小写模式中,由于不分大小写的英文是 Case-Insensitive,那么对应的模式标识就是 I 的小写字母 i,所以不区分大小写的 cat 就可以写成 (?i)cat。
也可以用它来尝试匹配两个连续出现的 cat,如下图所示,你会发现,即便是第一个 cat 和第二个 cat 大小写不一致,也可以匹配上。
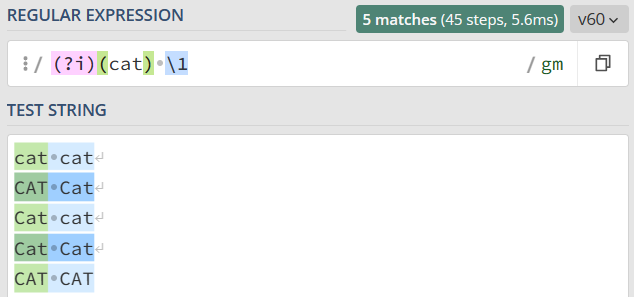
如果我们想要前面匹配上的结果,和第二次重复时的大小写一致,那该怎么做呢?我们只需要用括号把修饰符和正则 cat 部分括起来,加括号相当于作用范围的限定,让不区分大小写只作用于这个括号里的内容。
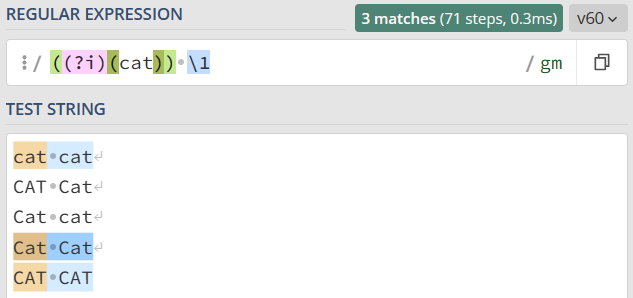
如果用正则匹配,实现部分区分大小写,另一部分不区分大小写,这该如何操作呢?就比如说现在想要,the cat 中的 the 区分大小写,cat 不区分大小写。
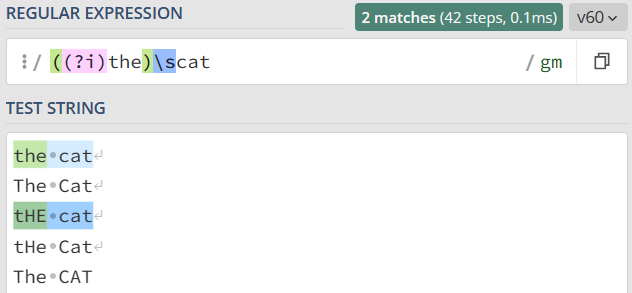
有一点需要注意一下,上面讲到的通过修饰符指定匹配模式的方式,在大部分编程语言中都是可以直接使用的,在 JS 中我们可以使用 /regex/i 来指定匹配模式。在编程语言中通常会提供一些预定义的常量,来进行匹配模式的指定。
2)点号通配模式(Dot All)
当我们需要匹配真正的“任意”符号的时候,可以使用 [\s\S] 或 [\d\D] 或 [\w\W] 等。
但是这么写不够简洁自然,所以正则中提供了一种模式,让英文的点(.)可以匹配上包括换行的任何字符。
这个模式就是点号通配模式,有很多地方把它称作单行匹配模式,但这么说容易造成误解,毕竟它与多行匹配模式没有联系,因此我们统一用更容易理解的“点号通配模式”。
单行的英文表示是 Single Line,单行模式对应的修饰符是 (?s),我还是选择用 the cat 来给你举一个点号通配模式的例子。如下图所示:
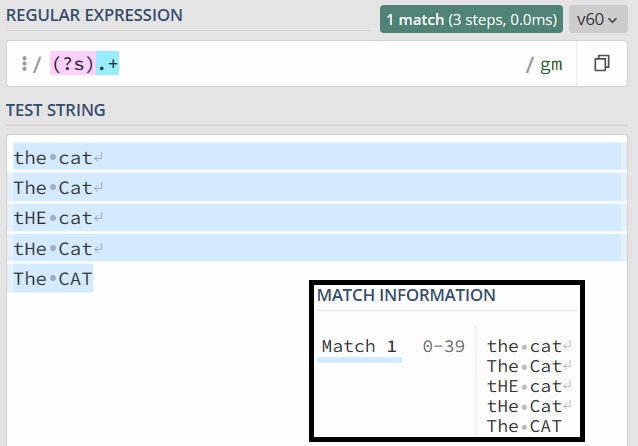
需要注意的是,JavasScript 不支持此模式,那么我们就可以使用前面说的 [\s\S] 等方式替代。
3)多行匹配模式(Multiline)
多行匹配模式(Multiline mode)是正则表达式中的一种模式,它改变了锚点 ^ 和 $ 的行为。在多行模式下,^ 和 $ 不再仅仅匹配整个字符串的开头和结尾,而是匹配每行的开头和结尾。
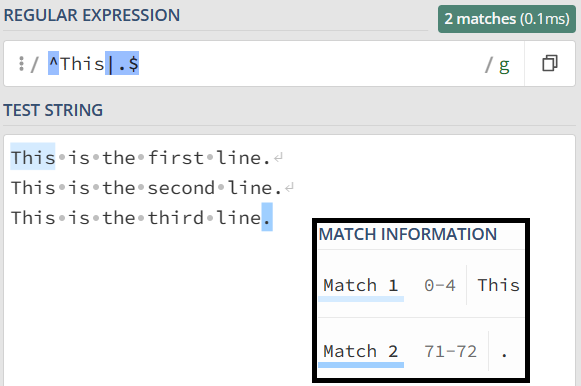
举个例子,考虑一个包含多行文本的字符串。在默认模式下,^ 只匹配整个字符串的开头,而在多行模式下,^ 将匹配每行的开头。同样地,$ 在多行模式下将匹配每行的结尾,而不仅仅是整个字符串的结尾。
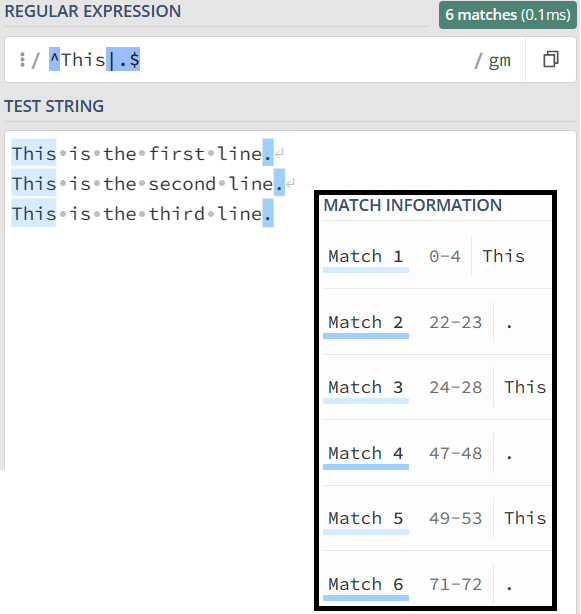
在一些正则表达式引擎中,多行模式可以通过 (?m) 修饰符来启用。
多行模式对于需要处理多行文本的情况非常有用,它可以让你更方便地操作每行的内容,而不必受制于整个字符串的开头和结尾。
当使用多行模式时,正则表达式中的 \A 和 \z(或 \Z)将严格匹配整个字符串的开头和结尾,而不受多行模式的影响。
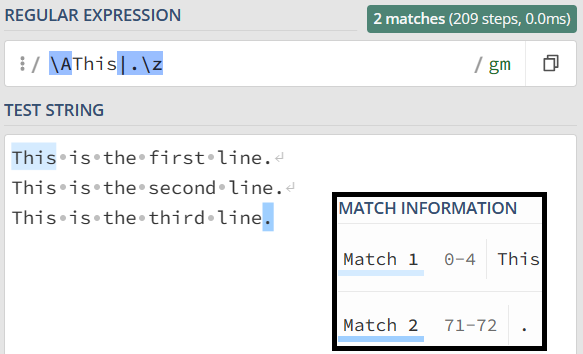
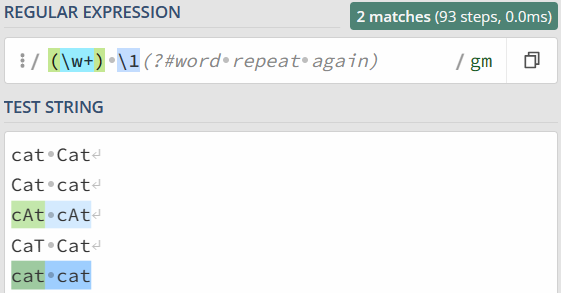
4)注释模式(Comment)
正则中注释模式是使用 (?#comment) 来表示。
2. JS 中使用
正则表达式在执行时会按他们的默认执行方式进行,但有时候默认的处理方式总不能满足我们的需求,所以可以使用模式修正符更改默认方式。
| 修饰符 | 说明 |
|---|---|
| i | 不区分大小写字母的匹配 |
| g | 全局搜索所有匹配内容 |
| m | 视为多行 |
| s | 视为单行忽略换行符,使用 . 可以匹配所有字符 |
| y | 从 regexp.lastIndex 开始匹配 |
| u | 正确处理四个字符的 UTF-16 编码 |
1)m
用于将内容视为多行匹配,主要是对 ^ 和 $ 的修饰。
将下面以 #数字 开始的课程解析为对象结构,学习过后面讲到的原子组可以让代码简单些。
let hd = `
#1 js,200元 #
#2 php,300元 #
#9 houdunren.com #
#3 node.js,180元 #
`;
// [{name:'js',price:'200元'}]
let lessons = hd.match(/^\s*#\d+\s+.+\s+#$/gm).map(v => {
v = v.replace(/\s*#\d+\s*/, "").replace(/\s+#/, "");
[name, price] = v.split(",");
return { name, price };
});
console.log(JSON.stringify(lessons, null, 2));2)u
每个字符都有属性,如 L 属性表示是字母,P 表示标点符号,需要结合 u 模式才有效。其他属性简写可以访问属性的别名网站查看。
//使用\p{L}属性匹配字母
let hd = "hello,我们正在学习JavaScript,加油!--2050年";
console.log(hd.match(/\p{L}+/u));
//使用\p{P}属性匹配标点
console.log(hd.match(/\p{P}+/gu));字符也有 unicode 文字系统属性 Script=文字系统,下面是使用 \p{sc=Han} 获取中文字符 han 为中文系统,其他语言请查看文字语言表。
let hd = `
张三:010-99999999,李四:020-88888888`;
let res = hd.match(/\p{sc=Han}+/gu);
console.log(res);使用 u 模式可以正确处理四个字符的 UTF-16 字节编码。
let str = "𝒳𝒴";
console.table(str.match(/[𝒳𝒴]/)); //结果为乱字符"�"
console.table(str.match(/[𝒳𝒴]/u)); //结果正确 "𝒳"3)lastIndex
RegExp 对象 lastIndex 属性可以返回或者设置正则表达式开始匹配的位置。
- 必须结合
g修饰符使用。 - 对
exec方法有效。 - 匹配完成时,
lastIndex会被重置为 0。
let xq = `hello,我们正在学习JavaScript,加油! --2050年`;
let reg = /JavaScript(.{2})/g;
reg.lastIndex = 10; //从索引10开始搜索
console.log(reg.exec(xq));
console.log(reg.lastIndex);
reg = /\p{sc=Han}/gu;
while ((res = reg.exec(xq))) {
console.log(res[0]);
}4)y
我们来对比使用 y 与 g 模式,使用 g 模式会一直匹配字符串。
let xq = "Ubuntu";
let reg = /u/g;
console.log(reg.exec(xq));
console.log(reg.lastIndex); //1
console.log(reg.exec(xq));
console.log(reg.lastIndex); //5
console.log(reg.exec(xq)); //null
console.log(reg.lastIndex); //0但使用 y 模式后如果从 lastIndex 开始匹配不成功就不继续匹配了。
let xq = "Ubuntu";
let reg = /u/y;
console.log(reg.exec(xq));
console.log(reg.lastIndex); //1
console.log(reg.exec(hd)); //null
console.log(reg.lastIndex); //0因为使用 y 模式可以在匹配不到时停止匹配,在匹配下面字符中的 qq 时可以提高匹配效率。
let hd = `JavaScript交流QQ群:11111111,999999999,88888888
后续会不断分享视频教程,网址是 baidu.com`;
let reg = /(\d+),?/y;
reg.lastIndex = 7;
while ((res = reg.exec(hd))) console.log(res[1]);六、断言
断言是指对匹配到的文本位置有要求。常见的断言有三种:单词边界、行的开始或结束以及环视。
1. 单词边界(Word Boundary)
想要把下面文本中的 tom 替换成 jerry。注意一下,在文本中出现了 tomorrow 这个单词,tomorrow 也是以 tom 开头的。
tom asked me if I would go fishing with him tomorrow.那正则是如何解决这个问题的呢?单词的组成一般可以用元字符 \w+ 来表示,\w 包括了大小写字母、下划线和数字(即 [A-Za-z0-9_])。那如果我们能找出单词的边界,也就是当出现了 \w 表示的范围以外的字符,比如引号、空格、标点、换行等这些符号,我们就可 以在正则中使用 \b 来表示单词的边界。\b 中的 b 可以理解为是边界(Boundary)这个单词的首字母。

根据刚刚学到的内容,在准确匹配单词时,我们使用 \b\w+\b 就可以实现了。
2. 行的开始或结束
和单词的边界类似,在正则中还有文本每行的开始和结束,如果我们要求匹配的内容要出现在一行文本开头或结尾,就可以使用 ^ 和 $ 来进行位置界定。
| 平台 | 换行符号 |
|---|---|
| Windows | \r\n |
| Linux | \n |
| macos | \n |
3. 环视(Look Around)
环视就是要求匹配部分的前面或后面要满足(或不满足)某种规则,有些地方也称环视为零宽断言。
举个例子:邮政编码的规则是第一位是 1-9,一共有 6 位数字组成。现在要求你写出一个正则,提取文本中的邮政编码。根据规则,我们很容易就可以写出邮编的组成 [1-9]\d{5}。
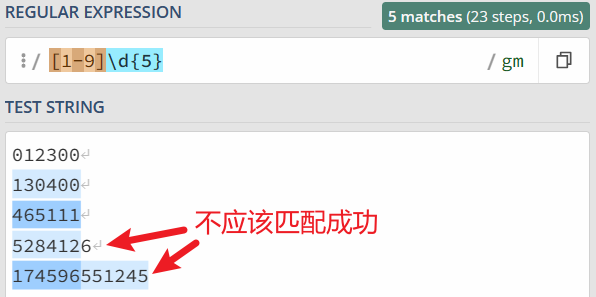
发现 7 位数的前 6 位也能匹配上,12 位数匹配上了两次,这显然是不符合要求的。解决这个问题的正则有四种。
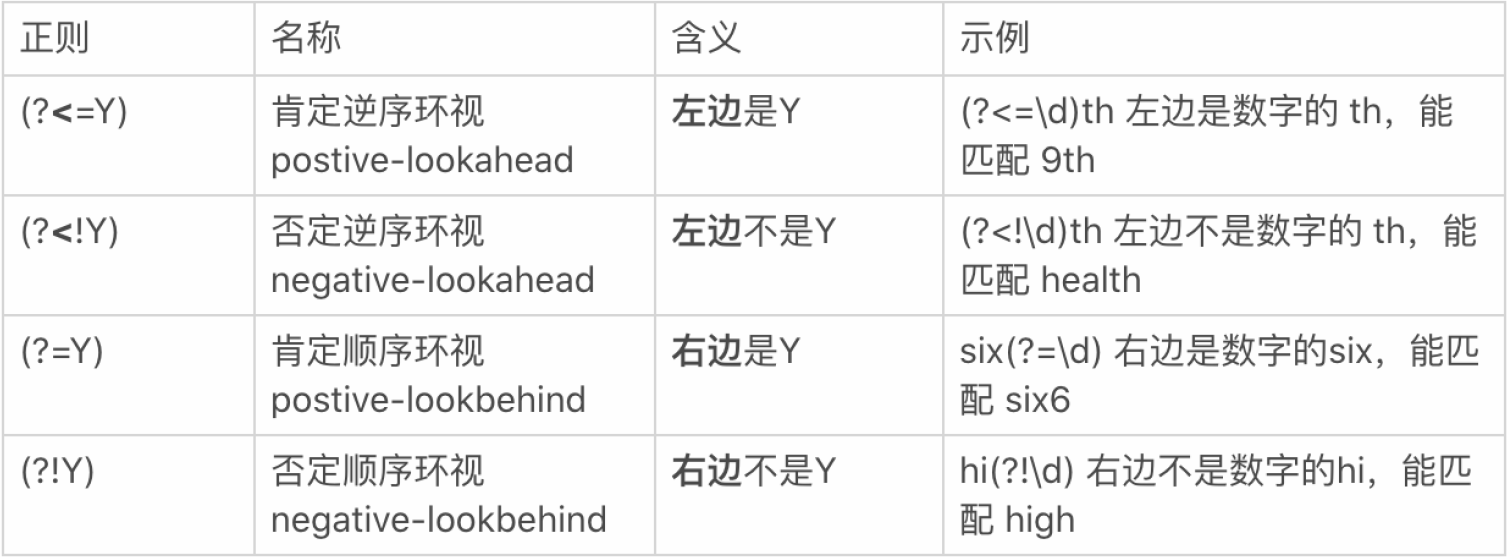
除了上面的名称,还有下面的叫法:
① 前瞻 / 正向先行断言(Positive Lookahead):用
(?=...)表示,它指定一个位置,该位置后面必须满足括号中的条件才能匹配。② 负前瞻 / 负向先行断言(Negative Lookahead):用
(?!...)表示,它指定一个位置,该位置后面必须不满足括号中的条件才能匹配。③ 后顾 / 正向后行断言(Positive Lookbehind):用
(?<=...)表示,它指定一个位置,该位置前面必须满足括号中的条件才能匹配。④ 负后顾 / 负向后行断言(Negative Lookbehind):用
(?<!...)表示,它指定一个位置,该位置前面必须不满足括号中的条件才能匹配。
口诀:左尖括号代表看左边,没有尖括号是看右边,感叹号是非的意思。
因此,针对刚刚邮编的问题,就可以写成左边不是数字,右边也不是数字的 6 位数的正则。即 (?<!\d)[1-9]\d{5}(?!\d)。
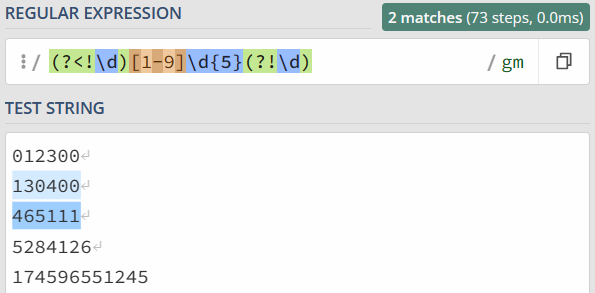
发散下思维,想想表示单词边界的 \b 如何用环视的方式来写?
比如下面这句话:
the little cat is in the hatthe 左侧是行首,右侧是空格;hat 右侧是行尾,左侧是空格;其它单词左右都是空格。所有单词左右都不是 \w。
(?<!\w) 表示左边不能是单词组成字符,(?!\w) 右边不能是单词组成字符,即 \b\w+\b 也可以写成 (?<!\w)\w+(?!\w)。
另外,根据前面学到的知识,非 \w 也可以用 \W 来表示。那单词的正则可以写成 (?<=\W)\w+(?=\W)。
环视中虽然也有括号,但不会保存成子组。保存成子组的一般是匹配到的文本内容,后续用于替换等操作,而环视是表示对文本左右环境的要求,即环视只匹配位置,不匹配文本内容。
练习
前面用正则分组引用来实现替换重复出现的单词,其实之前写的正则是不严谨的,在一些场景下,其实是不能正常工作的。如下,文本中 cat 和 cat2,还有 hat 和 hat2 其实是不同的单词。
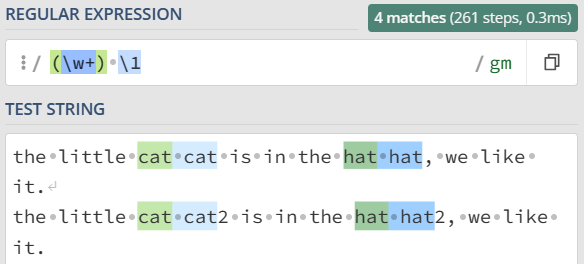
使用今天学到的知识来完善一下:
the little cat cat is in the hat hat, we like it.
the little cat cat2 is in the hat hat2, we like it.应该能想到在 \w+ 左右加上单词边界 \b 来解决这个问题。
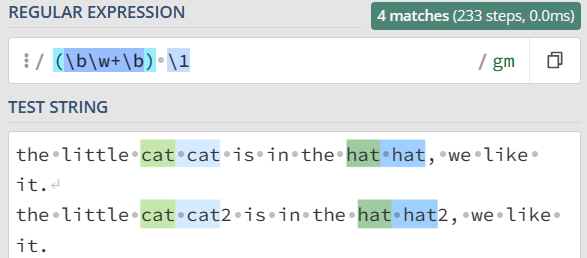
在使用分组引用时,前面的断言(如单词边界 \b)并不会被包含在内。分组引用只会匹配到原本的分组内容,不包括前面的断言。这意味着,如果我们使用 \b(\w+)\b \1 来匹配重复的单词,它将无法正确地处理像 "cat cat2" 这样的情况。
答案:(\w+)\s+\b\1\b
七、嵌入条件
1)根据一个回溯引用来进行条件处理。(?(回溯引用)true-regex)、(?(回溯引用)true-regex|false-regex)
2)根据一个前后查找来进行条件处理。(?(前后查找)true-regex)、(?(前后查找)true-regex|false-regex)
第三章:匹配原理及优化原则
正则之所以能够处理复杂文本,就是因为采用了有穷状态自动机(finite automaton)。
那什么是有穷自动机呢?有穷状态是指一个系统具有有穷个状态,不同的状态代表不同的意义。自动机是指系统可以根据相应的条件,在不同的状态下进行转移。从一个初始状态,根据对应的操作(比如录入的字符集)执行状态转移,最终达到终止状态(可能有一到多个终止状态)。
有穷自动机的具体实现称为正则引擎,主要有 DFA 和 NFA 两种,其中 NFA 又分为传统的 NFA 和 POSIX NFA。
DFA:确定性有穷自动机(Deterministic finite automaton)
NFA:非确定性有穷自动机(Non-deterministic finite automaton)
一、正则的匹配过程
在使用到编程语言时,我们经常会“编译”一下正则表达式,来提升效率。这个编译的过程,其实就是生成自动机的过程,正则引擎会拿着这个自动机去和字符串进行匹配。

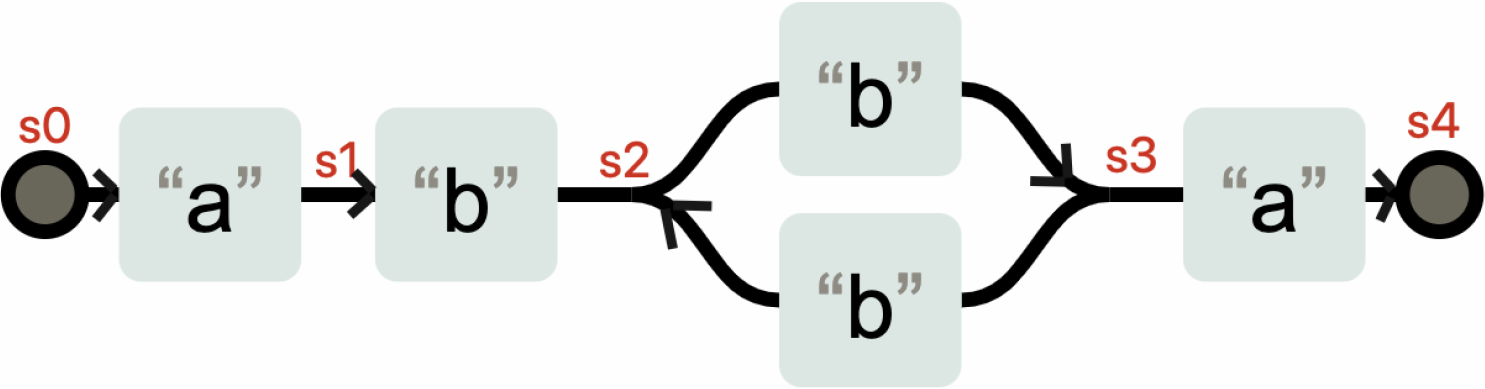
在状态 s3 时,不需要输入任何字符,状态也有可能转换成 s1。你可以理解成 a(bb)+a 在匹配了字符 abb 之后,到底在 s3 状态,还是在 s1 状态,这是不确定的。这种状态机就是非确定性有穷状态自动机(Non-deterministic finite automaton 简称 NFA)。
NFA 和 DFA 是可以相互转化的,当我们把上面的状态表示成下面这样,就是一台 DFA 状态机了,因为在 s0-s4 这几个状态,每个状态都需要特定的输入,才能发生状态变化。
二、DFA & NFA 工作机制
字符串:we study on jikeshijian app
正则:jike(zhushou|shijian|shixi)NFA 引擎的工作方式是,先看正则,再看文本,而且以正则为主导。正则中的第一个字符是 j,NFA 引擎在字符串中查找 j,接着匹配其后是否为 i,如果是 i 则继续,这样一直找到 jike。
regex: jike(zhushou|shijian|shixi)
^
text: we study on jikeshijian app
^再根据正则看文本后面是不是 z,发现不是,此时 zhushou 分支淘汰。
regex: jike(zhushou|shijian|shixi)
^
淘汰此分支(zhushou)
text: we study on jikeshijian app
^我们接着看其它的分支,看文本部分是不是 s,直到 shijian 整个匹配上。shijian 在匹配过程中如果不失败,就不会看后面的 shixi 分支。(当匹配上了 shijian 后,整个文本匹配完毕,也不会再看 shixi 分支)。
假设这里文本改一下,把 jikeshijian 变成 jikeshixi,正则 shijian 的 j 匹配不上时 shixi 的 x,会接着使用正则 shixi 来进行匹配,重新从 s 开始(NFA 引擎会记住这里)。
第二个分支匹配失败
regex: jike(zhushou|shijian|shixi)
^
淘汰此分支(正则j匹配不上文本x)
text: we study on jikeshixi app
^
再次尝试第三个分支
regex: jike(zhushou|shijian|shixi)
^
text: we study on jikeshixi app
^也就是说, NFA 是以正则为主导,反复测试字符串,这样字符串中同一部分,有可能被反复测试很多次。
而 DFA 不是这样的,DFA 会先看文本,再看正则表达式,是以文本为主导的。在具体匹配过程中,DFA 会从 we 中的 w 开始依次查找 j,定位到 j ,这个字符后面是 i。所以我们接着看正则部分是否有 i ,如果正则后面是个 i ,那就以同样的方式,匹配到后面的 ke。
text: we study on jikeshijian app
^
regex: jike(zhushou|shijian|shixi)
^继续进行匹配,文本 e 后面是字符 s ,DFA 接着看正则表达式部分,此时 zhushou 分支被淘汰,开头是 s 的分支 shijian 和 shixi 符合要求。
text: we study on jikeshijian app
^
regex: jike(zhushou|shijian|shixi)
^ ^ ^
淘汰 符合 符合然后 DFA 依次检查字符串,检测到 shijian 中的 j 时,只有 shijian 分支符合,淘汰 shixi,接着看分别文本后面的 ian,和正则比较,匹配成功。
text: we study on jikeshijian app
^
regex: jike(zhushou|shijian|shixi)
^ ^
符合 淘汰从这个示例你可以看到,DFA 和 NFA 两种引擎的工作方式完全不同。NFA 是以表达式为主导的,先看正则表达式,再看文本。而 DFA 则是以文本为主导,先看文本,再看正则表达式。
一般来说,DFA 引擎会更快一些,因为整个匹配过程中,字符串只看一遍,不会发生回溯,相同的字符不会被测试两次。也就是说 DFA 引擎执行的时间一般是线性的。DFA 引擎可以确保匹配到可能的最长字符串。但由于 DFA 引擎只包含有限的状态,所以它没有反向引用功能;并且因为它不构造显示扩展,它也不支持捕获子组。
NFA 以表达式为主导,它的引擎是使用贪心匹配回溯算法实现。NFA 通过构造特定扩展,支持子组和反向引用。但由于 NFA 引擎会发生回溯,即它会对字符串中的同一部分,进行很多次对比。因此,在最坏情况下,它的执行速度可能非常慢。
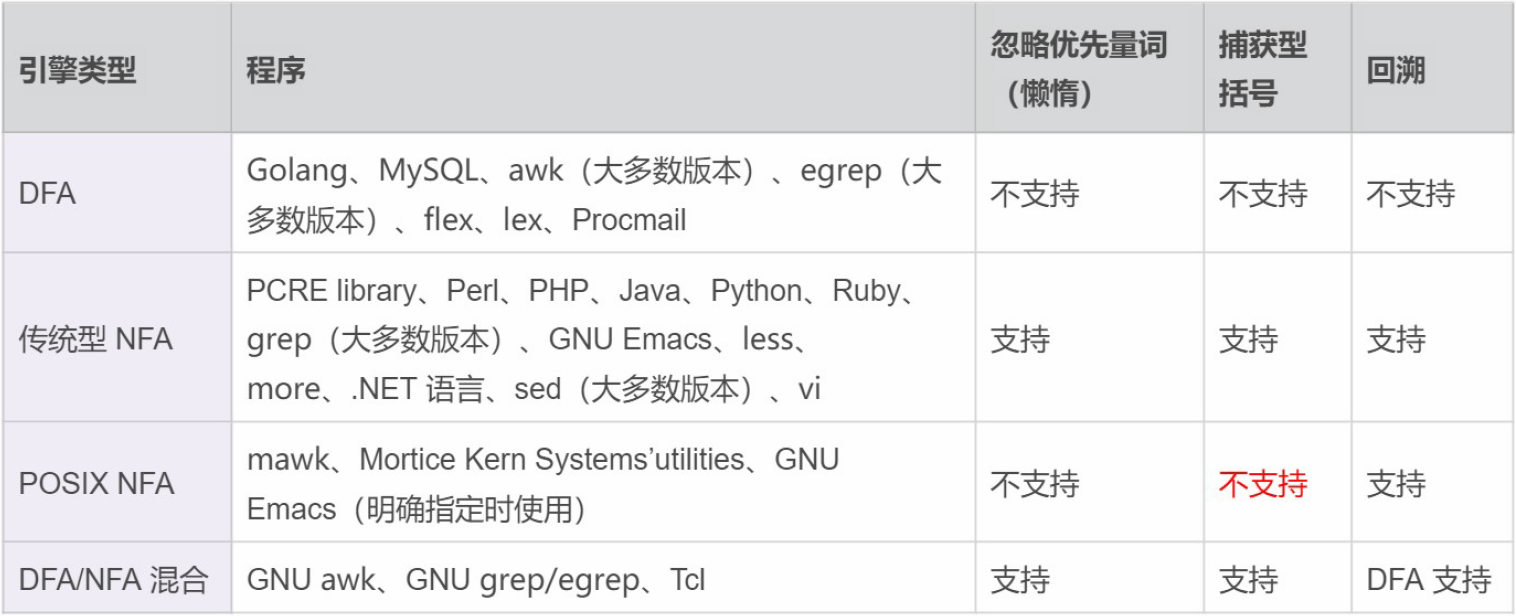
三、POSIX NFA 与传统 NFA 区别
因为传统的 NFA 引擎“急于”报告匹配结果,找到第一个匹配上的就返回了,所以可能会导致还有更长的匹配未被发现。比如使用正则 pos|posix 在文本 posix 中进行匹配,传统的 NFA 从文本中找到的是 pos,而不是 posix,而 POSIX NFA 找到的是 posix。
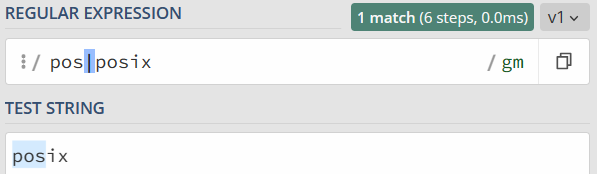
POSIX NFA 的应用很少,主要是 Unix/Linux 中的某些工具。POSIX NFA 引擎与传统的 NFA 引擎类似,但不同之处在于,POSIX NFA 在找到可能的最长匹配之前会继续回溯,也就是说它会尽可能找最长的,如果分支一样长,以最左边的为准(“The Longest-Leftmost”)。因此,POSIX NFA 引擎的速度要慢于传统的 NFA 引擎。
我们日常面对的,一般都是传统的 NFA,所以通常都是最左侧的分支优先,在书写正则的时候务必要注意这一点。
四、回溯
回溯是 NFA 引擎才有的,并且只有在正则中出现量词或多选分支结构时,才可能会发生回溯。
比如我们使用正则 a+ab 来匹配文本 aab 的时候,过程是这样的,a+ 是贪婪匹配,会占用掉文本中的两个 a,但正则接着又是 a,文本部分只剩下 b,只能通过回溯,让 a+ 吐出一个 a,再次尝试。
如果正则是使用 .*ab 去匹配一个比较长的字符串就更糟糕了,因为 .* 会吃掉整个字符串(不考虑换行,假设文本中没有换行),然后,你会发现正则中还有 ab 没匹配到内容,只能将 .* 匹配上的字符串吐出一个字符,再尝试,还不行,再吐出一个,不断尝试。

所以在工作中,我们要尽量不用 .* ,除非真的有必要,因为点能匹配的范围太广了,我们要尽可能精确。常见的解决方式有两种,比如要提取引号中的内容时,使用 "[^"]+",或者使用非贪婪的方式 ".+?",来减少 “ 匹配上的内容不断吐出,再次尝试 ” 的过程。
五、优化建议
提前编译好正则。
尽量准确表示匹配范围。
比如我们要匹配引号里面的内容,除了写成
".+?"之外,我们可以写成"[^"]+"。使用[^"]要比使用点号好很多,虽然使用的是贪婪模式,但它不会出现点号将引号匹配上,再吐出的问题。提取出公共部分。
出现可能性大的放左边。
只在必要时才使用子组。
警惕嵌套的子组重复。
如果一个组里面包含重复,接着这个组整体也可以重复,比如
(.\*)\*这个正则,匹配的次数会呈指数级增长,所以尽量不要写这样的正则。避免不同分支重复匹配。
第四章:编程语言中使用正则
一、Java
1)案例
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexpTest1 {
public static void main(String[] args) {
String context = "1995年,互联网的蓬勃发展给了Oak机会。业界为了使死板、单调的静态网页能够“灵活”起来,急需一种软件技术来开发一种程序," +
"这种程序可以通过网络传播并且能够跨平台运行。于是,世界各大IT企业为此纷纷投入了大量的人力、物力和财力。这个时候," +
"Sun公司想起了那个被搁置起来很久的Oak,并且重新审视了那个用软件编写的试验平台,由于它是按照嵌入式系统硬件平台体系结构进行编写的," +
"所以非常小,特别适用于网络上的传输系统,而Oak也是一种精简的语言,程序非常小,适合在网络上传输。Sun公司首先推出了可以嵌入网页" +
"并且可以随同网页在网络上传输的Applet(Applet是一种将小程序嵌入到网页中进行执行的技术),并将Oak更名为Java(在申请注册商标时," +
"发现Oak已经被人使用了,再想了一系列名字之后,最终,使用了提议者在喝一杯Java咖啡时无意提到的Java词语)。" +
"5月23日,Sun公司在Sun world会议上正式发布Java和HotJava浏览器。IBM、Apple、DEC、Adobe、HP、Oracle、Netscape和" +
"微软等各大公司都纷纷停止了自己的相关开发项目,竞相购买了Java使用许可证,并为自己的产品开发了相应的Java平台";
// 1. 提取文章中所有的英文单词
// 2. 提取文章中所有的数字
// 3. 提取文章中所有的英文单词和数字
// 传统方法:遍历方式 代码量大 效率不高
// 正则表达式方式
// 1.1 先创建一个 Pattern 对象,模式对象,可以理解成就是一个正则表达式对象
Pattern pattern1 = Pattern.compile("[a-zA-Z]+");
Pattern pattern2 = Pattern.compile("[1-9]+");
Pattern pattern3 = Pattern.compile("([1-9]+)|([a-zA-Z]+)");
// 1.2 再创建一个匹配器对象
// 理解:就是 matcher 匹配器按照 pattern 模式,到 content 文本中去匹配
Matcher matcher = pattern3.matcher(context);
// 1.3 可以开始循环匹配
while (matcher.find()){
// 匹配内容,文本,放到 m.group(0)
System.out.println("找到:"+matcher.group(0));
}
}
}2)原理
比如在一串文本中找到所有四个数字连在一起的子串:
public static void main(String[] args) {
String content = "1998年12月8日,第二代Java平台的企业版J2EE发布。1999年6月,Sun公司发布" +
"了第二代Java平台(简称为Java2)的3个版本:J2ME(Java2 Micro Edition,Java2平" +
"台的微型版),应用于移动、无线及有限资源的环境;J2SE(Java 2 Standard Edition," +
"Java 2平台的标准版),应用于桌面环境;J2EE(Java 2Enterprise Edition,Java 2" +
"平台的企业版),应用于基于Java的应用服务器。Java 2平台的发布,是Java发展过程中最重要" +
"的一个里程碑,标志着Java的应用开始普及。";
// 匹配所有四个数字
// 1. \\d 表示一个任意的数字
String regStr = "\\d\\d\\d\\d";
// 2. 创建 Pattern 对象
Pattern pattern = Pattern.compile(regStr);
// 3. 创建匹配器
// 说明:创建匹配器 matcher,按照 regStr 指定的规则去匹配 content 字符串
Matcher matcher = pattern.matcher(content);
// 4. 开始匹配
// 找到就返回 true,否则返回 false
// 匹配到的内容放入 matcher.group(0)
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}
}其中 matcher.find() 完成的任务有:
- 根据指定的规则,定位满足要求的字符串(比如:1998 )。
- 找到后,将子串索引记录到 matcher 对象的属性 int[] groups 中。比如子串1998,开始索引记录到 groups[0],即 groups[0] = 0;结束索引 +1 后记录到 groups[1] 中,即 groups[1] = 4。
- 记录 oldLast 的值为 groups[1] 的值,用来作为下次执行 find() 方法的匹配开始位置。
matcher.group(0) 分析: 源码:
public String group(int group) {
if (first < 0)
throw new IllegalStateException("No match found");
if (group < 0 || group > groupCount())
throw new IndexOutOfBoundsException("No group " + group);
if ((groups[group*2] == -1) || (groups[group*2+1] == -1))
return null;
return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
}上述可以概括为返回 [groups[0], groups[1]) 之间的子串,类似 subString 方法。
那么为什么是 group(0),这个 0 又代表什么意思?
对上述例子稍作修改,在 pattern 中加上两对小括号,如下:
// 匹配所有四个数字
// 1. \\d 表示一个任意的数字
String regStr = "(\\d\\d)(\\d\\d)";这样做相当于对正则表达式进行分组,有多少对括号就分成多少组,那么现在使用 matcher.find() 方法完成的任务有:
根据指定的规则,定位满足要求的字符串(比如:1998 )。
找到后,将子串索引记录到 matcher 对象的属性 int[] groups 中。
比如 1998,开始索引记录到 groups[0],即 groups[0] = 0; 结束索引 +1 后记录到 groups[1] 中,即 groups[1] = 4。
考虑分组,对于子串 1998,记录第 1 组() 匹配的字符串 19,groups[2] = 0,groups[3] = 2。
考虑分组,对于子串 1998,记录第 2 组() 匹配的字符串 98,groups[4] = 2,groups[5] = 4。
如果有更多的分组,以此类推。
记录 oldLast 的值为 groups[1] 的值,用来作为下次执行 find() 方法的匹配开始位置。
结论:分组后,groups 中 0 和 1 索引记录的仍为匹配到的子串的首尾索引,往后的位置依次记录分组对应的索引。
二、JavaScript
1)对象创建
[1] 字面量创建
正则表达式主要由两部分组成:模式(patterns)和修饰符(flags)。
使用 /pattern/flags 包裹的字面量创建方式是推荐的作法,但它不能在其中使用变量。
let xq = "hello Word";
console.log(/r/.test(xq)); // true下面尝试使用 a 变量时将不可以查询。
let xq = "hello Word";
let a = "r";
console.log(/a/.test(xq)); // false虽然可以使用 eval 转换为 js 语法来实现将变量解析到正则中,但是比较麻烦,所以有变量时建议使用下面的对象创建方式。
let xq = "hello Word";
let a = "r";
console.log(eval(`/${a}/`).test(xq)); // true[2] 对象创建
当正则需要动态创建时使用对象方式 new RegExp("pattern", "flags")。
let xq = "helloWord";
let web = "hello";
let reg = new RegExp(web);
console.log(reg.test(xq)); // true根据用户输入高亮显示内容,支持用户输入正则表达式。
<body>
<div id="content">baidu.com</div>
</body>
<script>
const content = prompt("请输入要搜索的内容,支持正则表达式。");
const reg = new RegExp(content, "g");
let body = document
.querySelector("#content")
.innerHTML.replace(reg, str => {
return `<span style="color:red">${str}</span>`;
});
document.body.innerHTML = body;
</script>通过对象创建正则提取标签。
<body>
<h1>baidu.com</h1>
<h1>qq.com</h1>
</body>
<script>
function element(tag) {
const html = document.body.innerHTML;
let reg = new RegExp("<(" + tag + ")>.+</\\1>", "g");
return html.match(reg);
}
console.table(element("h1"));
</script>重要代码解释:
"<(" + tag + ")>.+</\\1>": 这是正则表达式的模式字符串,其中<和>包围的部分表示了一个标签,tag是一个变量,用于动态地指定标签名。\\1表示对前面括号内捕获的内容的引用,这里表示对第一个括号内捕获的内容进行引用,以确保开始和结束标签匹配。.+表示匹配任意字符,+表示匹配一次或多次。"g": 这是正则表达式的标志,g表示全局匹配,即匹配所有符合条件的结果。在这个例子中,这个标志是多余的,因为match方法本身会自动匹配所有符合条件的结果。
2)JS 中使用
JavaScript 中的正则表达式被用于 RegExp 的 exec 和 test 方法;也包括 String 的 match 、matchAll 、replace 、search 和 split 方法。
| 方法 | 描述 |
|---|---|
| exec | 一个在字符串中执行查找匹配的 RegExp 方法,它返回一个数组(未匹配到则返回 null)。 |
| test | 一个在字符串中测试是否匹配的 RegExp 方法,它返回 true 或 false。 |
| match | 一个在字符串中执行查找匹配的 String 方法,它返回一个数组,在未匹配到时会返回 null。 |
| matchAll | 一个在字符串中执行查找所有匹配的 String 方法,它返回一个迭代器(iterator)。 |
| search | 一个在字符串中测试匹配的 String 方法,它返回匹配到的位置索引,或者在失败时返回 1。 |
| replace | 一个在字符串中执行查找匹配的 String 方法,并且使用替换字符串替换掉匹配到的子字符串。 |
| split | 一个使用正则表达式或者一个固定字符串分隔一个字符串,并将分隔后的子字符串存储到数组中的 String 方法。 |